
Table of Contents
Preface
By taking a directed reading course with Meren this past quarter, I had the opportunity to fulfill requirements for two graduate school bodies at the University of Chicago I am affiliated with: Committee on Microbiology and Genetics and Regulation Training. This course allowed me to dive into the history of metagenomics and how it has shaped our current understanding of microbial ecology and evolution.
To report on my journey, I decided to write a blogpost, summarizing ideas in the field that have shaped the questions I am addressing in my own research today. Specifically, I am interested in integrating environmental metagenomic data and genomics data to explore key insights into microbial fitness in environments such as the human gut and the oceans. My hope is that this blog post is approachable and accurate, and sets the stage for why I am able to ask these exciting questions. Please read the tangent boxes as they appear, they are meant to be read inline with the text.
Back to the Origins
It was difficult to find a starting point for the history of metagenomics. As a primer, I thought it would be great to begin before the word metagenomics was invented, with arguably the most prominent figure of microbial ecology and evolution, Carl Woese. His philosophical and experimental contributions to 16S ribosomal RNA gene amplicon sequencing is an important catalyst that launched us into the era of metagenomics because it opened our eyes to the unimaginable diversity of microbes. Let’s get started!
Carl Woese fundamentally changed our view of biological diversity by utilizing the 16S ribosomal RNA molecule as a phylogenetic marker. With this, he added to the tree of life ‘archaea’ as a new domain of life (Woese and Fox 1977), and primed 16S rRNA gene to be later used as a tool in high-throughput amplicon sequencing studies to explore microbial ecology. The Carl Woese’s review, “Bacterial Evolution”, is a microbial perspective written over 30 years ago and yet still feels relevant today (Woese 1987). The manuscript provided a breadth of reasoning and evidence for the utility of 16S rRNA gene as a phylogenetic marker in biology, as well as a source of wisdom and outlook on the field of microbiology. Although the majority of the review is describing arguments for the usage of 16S rRNA gene to explore bacterial evolution, I focused on the introductory sections that presented timeless ideas that I realized still impact the way I perceive metagenomics and microbiology today.
The “Perspective” chapter reads like a microbial op-ed, reflecting on how nucleic acid sequencing fundamentally changed our understanding of genetics and evolution, and how taxonomy before sequencing was, “a fruitless search”. Woese has a few epic quotes in this section that would be a injustice to paraphrase and are worth discussing more in-depth:
“The cell is basically a historical document, and gaining the capacity to read it (by sequencing of genes) cannot but drastically alter the way we look at all biology.” Woese, 1987
This premise highlights how microbiology research has been fundamentally technology driven. Our “capacity” to sequence genes drastically changed our understanding of diversity and protein evolution. What other technological innovations have pushed microbiology forward? Since the field of metagenomics rests on the technology of Next-Generation sequencing and Long-read sequencing, I was inspired to review origins of a few fundamental microbiology technologies. Please refer to footnotes for one of a few deeper dives into tangent topics (See Box 1).
(1) Technology catalyzed the first microbiology research I would argue that most knowledge about microbiology could not be discovered a priori. In fact, for 1000’s of years humanity had only interacted with the miracles (e.g. bread and beer) and disasters (e.g. pandemics) of microbial life using senses that could not elucidate the perpetrator (can we hear microbes?). Yet, there was an “apple falling from the tree” moment when Antony van Leeuwenhoek made technological improvements to the single lens light microscope. This Dutch scientist is referred to by many as the “Father of Microbiology” and is credited for discovering bacteria and protists! (Lane 2015)
The realization of the microbial world permanently changed our view of biological diversity; At the time, adding a new Kingdom. Yet, visually quantifying and categorizing microbes through microscopes had its limits. How could one assign metabolic abilities to a “species” when most microbes look the same in their natural community assemblages? To begin and ask questions about “What are they doing?” and “Who is there?” another innovation was required.
To address basic questions about microbial physiology and taxonomy, pure culturing techniques needed to be invented. Robert Koch is credited for developing the first microbial isolation techniques. He grew the first bacterial colonies on thin potato slices (Madigan et al. 2018)! Koch had the genius insight to assume that a colony was monoclonal and formed from a single colonizing bacteria. This catalyzed his research and allowed for the first pure culture (Reinkulturen) experiments. Koch’s assistant, Julius Richard Petri, expanded on Koch’s potato slices and invented, you guessed it, the Petri dish. This technological leap is responsible for the “Golden Age of Bacteriology’’ and an exponential increase in our knowledge of microbial diversity and function leading to discoveries such as antibiotics. Yet, as the century went on it became clear that culturing techniques were not keeping up with the immense diversity of microbes. Although there were many observations describing the discrepancy between the diversity of microbes that were able to be cultured versus those seen in microscopes, Staley et al. 1985 first deemed the problem as, “The Great Plate Count Anomaly” (Staley and Konopka 1985). We are still battling this culturing bias today and it has a new name, “The Uncultured Majority” (Sounds like a great New-Wave 80’s band) (Michael S. Rappé and Stephen J. Giovannoni).
The Prokaryote-Eukaryote dichotomy describes the idea that the definition of Prokaryotes was originally based on contrasting elements of Eukaryotes. Woese argued that taxonomy dogmas in biology have a tendency to distill and oversimplify categories e.g. plant versus animal. But the most impactful dichotomization of taxonomy came from the introduction of Prokaryote-Eukaryote distinction by Edouard Chatton (Sapp 2005). This chasm negatively defined Prokaryotes, as Woese put it, “Prokaryotes were initially defined in a purely negative sense: they did not have this or that feature seen in Eukaryotic cells.” This perspective may have perpetuated the idea that Escherichia coli could represent the genetics and physiology of all bacteria! In fact, Woese claims that it may have, “delayed the discovery of archaebacteria (Archaea) by well over a decade.” Maybe the Prokaryote-Eukaryote dichotomy is still shaping our view of biological diversity today? For example, some microbiome studies view the microbiome as another organ where a Prokaryotic perspective would view it as an ecosystem. Later in the blogpost I will discuss how metagenomics has brought us closer to understanding the evolution of Eukaryotes from an Archaeal ancestor.
Next, Woese discusses The Oparin-Haldane Hypothesis, colloquially known as the Primordial Soup Theory or the Heterotrophic Theory (Fry 2006). Briefly, this theory proposes that life occurred in primitive anaerobic oceans and the first organisms were “extreme heterotrophs” that assimilated already available, abiotically formed amino acids and nucleotides. When organic supplies ran low, this provided the evolutionary pressures to select for microorganisms with autotrophic capabilities. Woese reflects on this theory and how it may have also shaped our perception of Prokaryotes. He specifically highlights how the “pro-“ in Prokaryote has perpetuated the idea that Prokaryotes are more primitive and simple. Biological complexity is difficult to define. In the case of Prokaryotic vs Eukaryotic complexity I think the majority of arguments highlight the complexity of organelles and genetic regulation that Eukaryotes have. Yet in the context of metabolism, bacteria can access multiple terminal electron acceptors to generate ATP when the majority of Eukaryotes can only utilize Oxygen - who’s complex now??
“But if (and oh what a big if) we could conceive in some warm little pond with all sorts of ammonia and phosphoric salts, light, heat, electricity etcetera present, that a protein compound was chemically formed, ready to undergo still more complex changes […]” Darwin
Finally, Woese discusses the idea of Darwin’s “warm little pond,” an origin of life theory proposed by Darwin in a letter to Joseph Dalton Hooker in 1871 that is still popular today (Bada and Korenaga 2018)! In the letter, Darwin comments on the results of an experiment challenging Louis Pasteur’s interpretation of Spontaneous Generation (the belief that life spontaneously arose from abiotic materials - an explanation for putrefying food) (Madigan et al. 2018). Darwin’s description of the origin of life was in response to the Golden Age of Microbiology and all of the creative theories of the time to explain microbial life. Darwin’s “warm little pond,” scenario describes an origin of life story where life began in a lukewarm, aqueous environment when in reality we can only speculate the temperature of this critical event. Woese brilliantly phrases this idea with the question, “Do microbiologists perhaps view thermophilic bacteria as adaptations from mesophilic species for this reason? ‘Warm’ is an anthropocentrism.” This is an interesting observation because we deem extremophiles as temperatures that deviate from standard Earth surface norms, yet maybe the first life forms on this planet were in a much hotter environment… So what is extreme then?
The “Perspective” chapter of Carl Woese’s Bacterial Evolution set the tone of my literature dive to challenge perceptions in Metagenomics and dive deep into ideas that shaped the field today. Despite its critical role in ushering in the era of culture-independent research, I will not focus on 16S sequencing here, but will skip forward to the beginnings of metagenomic sequencing.
The first metagenomic sampling
16S rRNA gene sequencing studies expanded our understanding of microbial diversity and ecology, and ushered in the era of culture-independent studies. This era was catalyzed by improved PCR primers and economic Sanger sequencing. Although discoveries of novel microbial diversity seemed endless, limitations of amplicon sequencing began to arise. Cultured representatives could not keep up with the discovery of new phylotypes observed in the environment. This is a continued disconnect even today where it is very difficult to isolate ecologically relevant microbes and/or representatives of the total niche space of an environment. Due to this culturing bias it became hard to extrapolate metabolic capabilities and phenotypes of cultured representatives to newly discovered sequence phylotypes; more genomic context was needed. As Carl Woese puts it, “In the extreme, interspecies exchanges of genes could be so rampant, so broad spread, that a bacterium would not actually have a history in its own right; it would be an evolutionary chimera, each with its own history” (Woese 1987). One prominent example is Staphylococcus aureus. Strains that have identical marker genes, such as identical 16S rRNA genes, may have different antibiotic resistance phenotypes obtained from genomic islands via horizontal gene transfer. A new sequencing technique was needed to access more genetic information from environmental microbes to expand hypothesis generating capabilities.
Stein et al. 1996 recognized the limitations of amplicon sequence and pushed the field forward with the first attempt of metagenomic sequencing in Hawaiian ocean water (although the name metagenomic sequencing had not been coined yet) (See Box 2).
(2) Origin of the term metagenomics Where did the term ‘metagenomics’ come from? The term metagenomics was first coined by Jo Handelsman in her 1998 work, a few years after Stein et al. 1996. Interestingly, metagenomics was first used to describe an approach for biosynthetic gene cluster (BGC) research. Natural product discovery via BGC research at this point had been driven by microbial isolation with selective media to search for specific antibiotic and metabolic phenotypes. J. Handelsman et al. 1998 recognized how using an entire sample’s worth of DNA could be beneficial for accessing novel BGC loci (similar to how Stein et al. 1996 wanted to explore novel metabolisms in Archaea described below). The method described in this paper included cloning potential BGC genomic fragments from an environmental sample into E. coli vectors and phenotype screening. BGC research would no longer be constrained by the Great Plate Anomaly! The first sentence with the term metagenome:
“The methodology [cloning of environmental DNA into E. coli for phenotype screening] has been made possible by advances in molecular biology and Eukaryotic genomics, which have laid the groundwork for cloning and functional analysis of the collective genomes of soil microflora, which we term the metagenome of the soil.” J. Handelsman et al. 1998
Considering this is the first use of the term metagenomics, I want to take a second to break down its etymology. The prefix ‘meta-’ is Greek in origin and has a few applications including the inference of later, behind, or beyond in time and space (e.g. metacarpus). But when used as a prefix to a subject, it means the critical and/or abstract analysis of the subject (e.g. metaphysics, metalinguistics).
Genomics is the study of the genetic material of an organism. If genomics is a subject, the most direct interpretation of metagenomics would be, “to think abstractly about the genome.” Yet in the case of Handelsman et al., 1998 and even today’s field, this interpretation may not be appropriate. In fact, I believe meta- in the context of metagenomics is inferring “going beyond the genome.” Microbiology ecology had been constrained by amplifying taxonomic markers and extrapolating the functional potential of microbes by linking them to known isolates. For example, in BGC research, you had to use 16S amplicon sequencing to see if potential microbes of interest (e.g. actinomycetes) were in a specific environment, then hope they could grow in standard culture techniques and be screened for specific phenotypes. This is essentially accessing one genome at a time. Handelsman et al., 1998 explains how the metagenome, “the collective genome,” of the soil can now be accessed by cloning genomic fragments into Fosmid vectors and expressing them in E. coli. I would argue that this is essentially a survey of the functional potential of a microbial community, an ecological perspective. Maybe metagenomics was not the best word to describe our field? Regardless, it stuck and I do not have a problem with it.
Stein et al. 1996 posits that there is a need for culture-independent innovations because of the lack of cultured representatives of newly discovered phylotypes and examples of prokaryotic lineages having a large metabolic diversity of physiological capabilities. This manuscript looks to further culture-independent microbial ecology by investigating the marine Archaea clade, Creanrchaeota. They do this by going beyond surveying taxonomic markers of diversity via 16S and 18S rRNA amplicon sequencing. Instead, they extracted large fragments of genomic DNA (up to 40 Kb) from seawater and sequence via a Fosmid cloning approach. (See Box 3)
(3) Methods have changed Whoa! Metagenomic sequencing is different now… Shotgun metagenomic sequencing with Illumina methods have come a long way since the time of this paper. Stein et al. 1996 could not just perform a simple Illumina library preparation. Instead, they had to use an E. coli Fosmid cloning vector to generate their library of large DNA fragments from the marine environment (30 liters of seawater were filtered!). Furthermore, prior to their library prep, they performed a standard 16S rRNA screen on a subset of each sample to confirm there was Creanrchaeota genomic material in the sample. This makes sense considering how labor intensive and expensive this sequencing must have been at the time. Next, the DNA was digested using restriction enzymes to achieve smaller fragments and then cloned into the Fosmid vector library. The clones were then screened for specifically archaeal DNA fragments by amplifying 16S rRNA genes content from the fragments. Fragments that did not contain a part of the Crenarchaeota ribosomal subunit were not further sequenced. The clones that passed this stage were then prepared for sequencing. Final DNA sequences were analyzed for homology upstream and downstream of the 16S phylogenetic anchor against the NCBI NR protein database using BLAST. Glad we don’t have to do that anymore!
At this point, it was known that there were abundant marine Archaea in the surface ocean (DeLong et al. 1994; DeLong 1992; Fuhrman, McCallum, and Davis 1992), but there was no cultured representative, only amplicon marker gene evidence. “Although the genotypic and phenotypic properties of marine pelagic archaea are unknown at present, their abundance and ecological distribution suggest that they may represent entirely new phenotypic groups within the domain Archaea” (Stein et al. 1996). With only marker genes, inferences of metabolic capabilities can only be made by looking at phylogenetically similar cultured representatives. Leveraging metagenomic sequencing of large genomic fragments, Stein et al. 1996 could use “genomic walking” (looking upstream and downstream on genomic fragments from a phylogenetic marker) in the marine environment. In essence, their goal was to collect large fragments from picoplankton genomic DNA in an attempt to extract the genomic DNA from Crenarchaeota. By “walking” upstream and downstream from the phylogenetic marker, they hoped to obtain physiological insights.
Phylogenetic analysis revealed that 33% of genes found on the 40 kb fragments had significant homology to previously sequenced genes. Additionally, most genes located on the fragments were related to ribosomal proteins. Other notable genes included glutamate 1-semialdehyde transferase and RNA helicase, both of which are core microbial functions. Finally, there were examples of the entire 16S-23S operons found on fosmids. This cutting edge environmental sequencing study at the time was unfortunately constrained by the use of the 16S phylogenetic marker of Crenarchaeota. The genomic neighborhood that was explored by “genomic walking” only allowed the discovery of neighboring genes of core functions of Archaea and a highly studied area of genomes. If there was another phylogenetic marker of Archaea more related to metabolism, there could have been a chance to explore a more novel genomic neighborhood away from the 16S region. Although the findings of the paper did not reveal novel Archaeal metabolisms for the time, it laid groundwork for a new era of environmental shotgun sequencing.
Order to chaos - Extracting genomes from metagenomes
I next jumped ahead to another phase of the metagenomics progression, the era of genome-resolved metagenomics. Now that we had the ability to access the “collective genome” of an environmental sample, research was constrained by the immense amount of data. To address this data analysis challenge there were numerous data analysis innovations in comparative metagenomics from clustering orthologs (Yooseph et al. 2007) to gene catalogues (Turnbaugh et al. 2007). Yet as Katherine McMahon puts it, “Genes are expressed within cells, not in a homogenized cytoplasmic soup.” (McMahon 2015) In other words, the first comparative metagenomics projects were genome agnostic. It was like comparing a Jackson Pollock painting of functional potential to a Jean-Paul Riopelle painting of short reads. (See Box 4)
(4) Metagenomics Metaphor What are some good metaphors for metagenomics techniques? In the spirit of science communication here is my attempt: Genome-resolved metagenomics is like extracting patterns from a Jackson Pollock drip painting. At first it may seem like a random and cohesive mess (like an ecosystem). But one can begin to find order if you categorize each painting gesture into style (drip, slash, stroke) and color. This organization can deconstruct the painting into its original gestures that once seemed impossible to separate out (population genomes). What do we have in common between these two cohesive beautiful messes? Tyson et al. 2004 for the first time attempted to reconstruct genomes from short, metagenomic contigs - organizing short reads into replicas of the original genomic units.
The questions being explored in Tyson et al. 2004 were both methodologically and ecologically based. The technical question was whether it was possible to assemble and extract groups of metagenomic contigs that represent a collective genome from a population of similar microbes? The ecological question in this paper was what is the functional potential of the individual microbial community members in a low diversity biofilm found in an acid mine drainage (pH 0.83)? Understanding life in extreme environments is important for fundamental questions in regards to astrobiology and geobiology. Although there were cultured representatives of extreme acidic environments at the time, it was unclear if the naturally occurring community of this acidic biofilm mirrored the isolates taxonomically and metabolically.
To address these questions, Tyson et al. 2004 used unprecedentedly deep shotgun metagenomic sequencing (103,462 reads) to access the functional repertoire of this gnarly biofilm. Interestingly, they used the same method for DNA extraction as Stein et al. 1996 discussed above! Some other key strategies they implemented to prepare their data for genome reconstruction attempt were: (1) adjusting their assembly strategy to not penalize non-uniform read depth and (2) allowed read mapping of 95% identity. These two adjustments allowed for more contigs to be assembled from the environmental sample and would incorporate more variation in the final contigs.
Once contigs were assembled Tyson et al. 2004 grouped them together (“binned”) using GC content then subsequently refined the groups (“bins”) using differential coverage of short reads against the reference contigs. A bimodal distribution of contigs arose when statistics from their metagenomic contigs were visualized (Figure 1A) (Visualization of metagenomic bins has developed over the last 15 years, check out its progression in Figure 1). Tyson et al. 2004 highlighted that their success in reconstructing genomes from metagenomes in this environment was contingent upon the low diversity in the biofilm. The results of their binning yielded two “nearly complete” genomes and 3 partially recovered metagenomes (aka metagenomic assembled genomes - MAGs).
This was such a groundbreaking paper that it inspired me to go on two more tangential deep dives. First, they devised a computational method to reconstruct genomes from metagenomes leveraging nucleotide composition (see Box 5) and differential coverage.
(5) Origin of nucleotide content K-mer content, where did the idea of using nucleotide content for distinguishing genomes come from? Today we refer to nucleotide content in the context of metagenomics as k-mer content but Tyson et al. 2004 used GC content (i.e. a combination of Guanine and Cytosine 1-mers). Let’s take a look back and explore the evolution of kmers and genomes. As soon as DNA sequences were available scientists were examining them for patterns. In fact, the first time nucleotide composition patterns were discovered was in 1961 by Josse et al. 1961, “…each DNA directs the synthesis of a product which has a unique and non-random pattern of the 16 nearest neighbor frequencies;” (Josse, Kaiser, and Kornberg 1961). Later on, Subak-Sharp et al. 1966 went a step further in quantifying dinucleotide patterns in DNA sequences when looking for evolutionary sequence relationships with viral-host interactions (Subak-Sharpe et al. 1966). Additionally, great intellectual contributions to understanding how general patterns of nucleotide frequencies can separate taxonomic groups were made by Ruth Nussinov (Nussinov 1980, Nussinov 1984). In terms of GC content, it had been known that different bacterial taxa could be separated with this measurement which was determined via DNA denaturation from melting points (De Ley and Vanmuylem 1963). However, the first time GC content from nucleotide composition was used to examine bacterial taxonomy was by (Russell et al. 1973) (Figure 1).

K-mers of four (tetranucleotides) are the most popular methods to describe nucleotide content in metagenomics today. The first examples of tetranucleotide usage I could find was in 1984 to investigate methylation sites on post replicative methylation of adenine in E. coli (McClelland 1984). As more genomes became available, more nucleotide composition approaches arose for a variety of research topics. Specifically, scientists leveraged nucleotide content to develop classifiers to predict the genome of origin of short oligonucleotide sequences (Sandberg et al. 2001; Abe et al. 2003). This method sounds very similar to the idea of grouping short metagenomic contigs together into a bin. I see what you did there Tyson et al. 2004 ;)
This data analysis strategy began the transition of the field of metagenomics from primarily read-based based approaches to a genome-centric phase. Tyson et al. 2004 also took huge philosophical steps forward in defining the completeness of genomes recovered from metagenomes. Just because some statistics or algorithm says that a group of contigs look similar does not mean that an entire genome has been recovered, especially from a complex microbial community. Tyson et al. 2004 defined “completeness” of their bins accounting the amount of transfer RNA synthetases each genomic bin had. How does this hold up to today’s standards for MAG completeness, redundancy, and contamination? (see Box 6)
(6) What’s complete? The effort to standardize genome completeness has been around since before genome-resolved metagenomics (Mardis et al. 2002) and is still debated today (Bowers et al. 2017). Tyson et al. 2004 extracted the first population genomes from metagenomes and thus set the first standard for genome completeness which focused on the amount of transfer RNA synthetases a bin had as well as, “anticipated genome sizes,” and confirming, “that dividing scaffolds by GC content, read depth and homology to the fer1 genome”.
The concept of “completeness” of MAGs then progressed to looking at single-copy core genes (SCGs) in the bacterial tree of life. This was both inspired by finding a set of SCGs for concatenated alignments for phylogenetic purposes (Ciccarelli et al. 2006) as well as a way to predict genome size based on a set of SCGs (Raes et al. 2007). Later, SCGs evolved to be based on curated sets of Pfam Hidden Markov Models (HMMs) (Finn et al. 2016). This was accomplished by searching Pfams against bacterial genome databases of the time (e.g. Comprehensive Microbial Resource, IMG database) and selecting those that only occurred once in different thresholds of all genomes (e.g. 95-99%) (Dupont et al. 2011; Rinke et al. 2013). This style of SCG lists was pushed forward by Swan et al. 2013 who made a list of taxa specific SCGs (x > 95% for all bacteria then x > 99% for specific taxa). This is an interesting concept because as you increase resolution on the tree of life the list of SCGs from specific taxa should get larger. For example, cyanobacteria may have photosynthesis related SCGs that other taxa do not have, thus a cyanobacteria bin without this SCG is definitely not complete.
Another concept related to MAG completeness is contamination. Binning algorithms can add contigs to bins that in reality do not belong to the population genome. In the metagenomic sampling of activated sludge from a wastewater treatment plant, Albertsen et al. 2013 used a list of HMMs from Dupont et al. 2011 to describe “completeness” and for the first time “contamination” in their MAGs. Contamination was defined by counting the number of duplications of SCGs. A duplication of an SCGs would infer that a contig from another population was included into the MAG by mistake since by definition each SCG should only occur once.
A popular tool today to address completeness and contamination is checkM which uses lineage specific SCGs (Parks et al. 2015). The state of lineage specific SCGs will probably be in a constant state of fluctuation with the numerous new taxa that are added to the tree of life with every new large metagenomics project (Hug et al. 2016; Lee 2019).
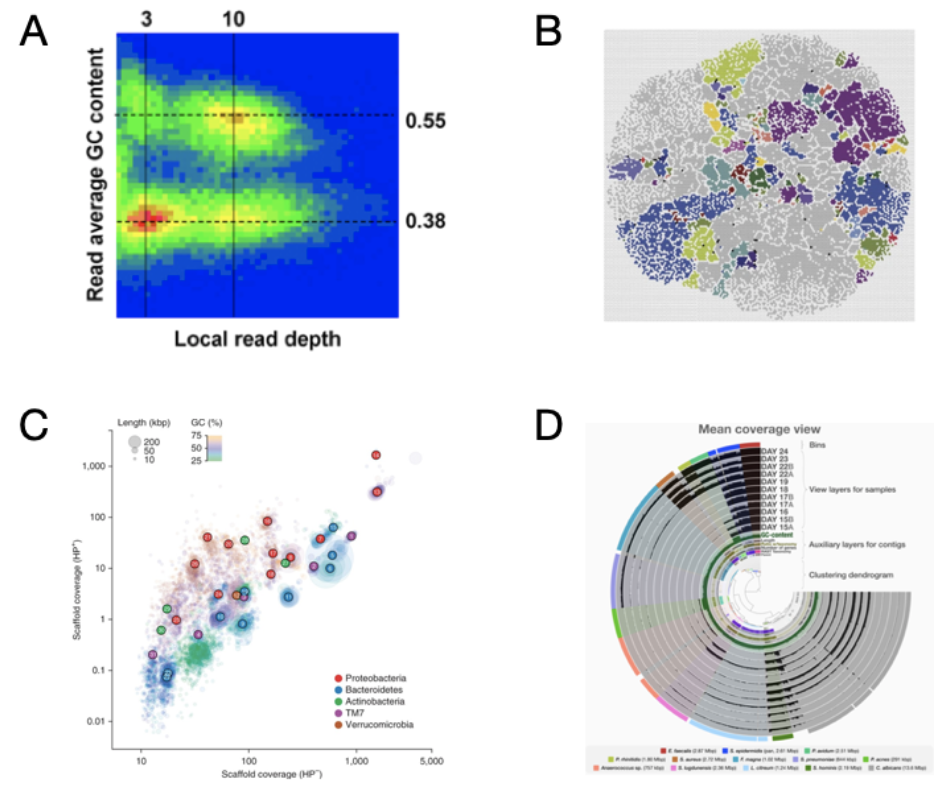
Figure 2. Progression of genome-resolved metagenomics visualizations (A) The first visualization of binned contigs using GC content and read depth coverage (Tyson et al. 2004). (B) Self-organizing map approach based on tetranucleotide z-scores (Weber et al. 2011). (C) Clustering of contig scaffoled based on contig read depth from two separate DNA extraction protocols, with and without hot phenol (HP+ and HP−), and colored by GC content (Albertsen et al. 2013). (D) Anvi’o interactive interface with contig clustering based on tetranucleotide content and differential read coverage from co-assembled metagenomic samples (Eren et al. 2015).
Leveraging Genome-resolved Metagenomics
Genome-resolved metagenomics has revolutionized our ability to understand uncultured microbes and catalyzed unprecedented discoveries that have impacted multiple fields from biogeochemistry to evolutionary biology. To me, metagenomics is an amazing hypothesis generator and at this point in this review I wanted to highlight some discoveries that were made possible from genome-resolved metagenomics.
Bioavailable nitrogen in the global oceans is a hot topic because of its impact on the carbon cycle and primary productivity. For how critical nitrogen is to the ocean ecosystem, a surprisingly small group of Cyanobacteria (e.g. UCYN-A and Trichodesmium) are theorized to be responsible for the majority of nitrogen fixation in the global oceans. Other Bacterial phyla such Proteobacteria and Firmicutes have been linked to nitrogen fixation via PCR amplicon studies of the nifH gene. Although, surveys showed that these nitrogen fixers (diazotrophs) tend to be from the rare biosphere (in very low abundance) with only a few cultured representatives. This left a significant knowledge gap in terms of the function potential of these enigmatic diazotrophs and how they impact biogeochemistry. Delmont et al. 2018 leveraged metagenomic binning and extracted ~ 1000 MAGs from the Tara Oceans Project (A global ocean microbiome sampling effort with unprecedentedly deep sequencing) (Sunagawa et al. 2015). Some of these newly extracted MAGs contained nitrogen fixing capability! One interesting highlight from these MAGs was for the first time, Planctomycetes was associated with diazotrophic capabilities. Genome-resolved metagenomics permitted access to uncultured microbes with key biogeochemical capabilities and revealed the rest of their metabolic potential. By putting contigs with nitrogen fixing genes into genomic context, we can now create targeted culturing campaigns to isolate these novel diazotrophs.
MAGs have catalyzed bacterial phylogenomics of uncultured microbes. Brown et al. 2015 leverage MAGs from deep aquifer groundwater to unveil more than 35 new bacterial phylums deemed candidate phyla radiation (CPR). This unveiled extraordinary microbial diversity that was never shown using 16S amplicon surveys because the 16S rRNA gene sequences these enigmatic CPR were too divergent for standard bacterial primers. Metagenomic sequencing is a less biased sequencing approach compared to PCR based approaches because there is no amplification step, thus allowing for more microbial biodiversity to be uncovered. Hug et al. 2016 leveraged this new set of CPR genomes and re-calculated the tree of life leveraging phylogenomics which included all domains. Without MAGs, the genes necessary to make a concatenated single-copy core gene alignments would not have been possible.
MAGs have re-rooted our interpretation of the origin of Eukaryotes. MAGs from the bottom of the ocean (really, the bottom of the ocean in a hydrothermal vent) revealed a whole new class of archaea that contain Eukaryotic-like genes (Asgard archaea named after Scandinavian gods). Spang et al. 2015 proposed that the tree of life has two, not three, branches. In other words, Eukaryotes branched off from a more ancient archaeal branch. This is a highly debated topic where other groups have claimed there are still 3 branches (Da Cunha et al. 2017). These analyses were only possible through putting contigs in a genomic context through binning which allowed for a phylogenomic approach to place these undiscovered genomes on a provocative branch of the tree of life.
The discoveries described above have all relied upon putting metagenomic assembled contigs into the genomic context of a microbial population genome. Although binning metagenomic contigs has the potential to yield a mosaic mixture of microbial populations, careful curation can yield MAGs with high probability of accuracy. In essence, MAGs have given scientists access to the genomic potential of microbes that are not yet cultured and maybe the unculturable! Although there are many inherent limitations to binning, MAGs are a great hypothesis generation tool that can inspire new cultivation experiments that could have never been imagined. Imachi et al. 2020 spent 12 years enriching for Asgard archaea from marine sediment 2,533 m below sea level (using powdered milk as one of their media ingredients!). This archaea named ‘Candidatus Prometheoarchaeum syntrophicumthus’ was a literal missing-link for evidence of the endosymbiotic theory. I would argue that motivation for a decade-long enrichment experiment would have dwindled if it were not for discoveries such as (Spang et al. 2015).
Metagenomics: Present and Future
Massive Genome and MAG datasets
The influx of genomes and MAGs in recent years has encouraged new data analysis techniques to explore the Prokaryotic protein sequence space and gene content variation at different phylogenetic resolutions. As Next-Generation deep sequencing became more affordable, sequencing depth of metagenomics projects increased. This has allowed for the creation of higher quality MAGs due to the emergence of coverage senstivitive algorithms for binning.
In the last 5 years, numerous large-scale metagenomic sampling projects have produced enormous data sets of MAGs (Almeida et al. 2019; Parks et al. 2017; Pasolli et al. 2019; Delmont et al. 2018). These datasets have added a significant amount of new diversity to the tree of life and provide a way forward to explore the uncultured majority of microbes. Additionally, significant steps have been taken to expand our knowledge of the human gut microbiome due to its correlation with health and disease (Almeida et al. 2019; Pasolli et al. 2019). Pasolli et al. 2019 highlighted how different non-western gut microbiomes are from western microbiomes and how significantly undersampled they are. With massive publicly available MAG datasets, large meta-analyses can be performed and questions relating to global prevalence of bacterial taxa or proteins can be achieved. Additionally, the microbial tree of life has begun to transition from phylogenetics (marker genes) to phylogenomics (concatenated single-copy core genes) based approaches (Parks et al. 2018). We can now address questions about microbial functions on the tree of life scale because of the availability of genomes in phylogenomic trees. For example, one can ask about a microbial function and how taxonomically constrained it is (e.g. photosynthesis being constrained to cyanobacteria). This broad understanding of the microbial tree of life will allow scientists to elucidate evolutionary questions like never before.
Data analysis and integration with ecology
I would argue that we are now transitioning from a genome-centric phase into a new high resolution phase in the field, Metagenomics 3.0. The themes of this next phase will revolve around the innovation of data analysis techniques that allow us to compare genomes and MAGs at high resolution, perform deep homology searches (Steinegger and Söding 2017), and explore their ecological relevance on a global scale. Although within strain variation of bacteria has been explored since the first MAGs were binned (Simmons et al. 2008), the excess of genomic data we now have at our disposal will allow us to address not only high resolution strain variation questions but broad questions about the total sequence variability and gene content within large phylogenetic groups. One method that can be used to explore this gene content and sequence variability is pangenomics (see Box 7).
(7) Origins of pangenomics What are the origins of pangenomics? Well ever since there were multiple bacterial genomes available for the same species, questions regarding sequence and gene content variation have been explored (Perna et al. 2001). The first microbial pangenome was calculated by Tettelin et al. 2005 when investigating the genetic variability of six strains of Streptococcus agalactiae serotypes to find new genome-wide vaccine and antimicrobial targets. They chose the prefix “pan-“ because of its Greek root meaning of whole. In this 8 strain pangenome, Tettelin et al. 2005 noted that there was a core set of genes shared by all genomes and made ~80% of the content for each. This was the first mention of the idea of core and accessory (referred to as “dispensable”) genes (discussed later in the post). The large amount of genomes and MAGs available have allowed for interesting theories to arise about how the accessory genome impacts evolution of species (Medini et al. 2005; McInerney, McNally, and O’Connell 2017), as well as if the accessory genome is under adaptive evolution (Iranzo et al. 2019; Maistrenko et al. 2020; Vos and Eyre-Walker 2017; Van Rossum et al. 2020).
Pangenomics is essentially a Venn diagram of gene content between closely related genomes. Briefly, the method clusters together all genes from a set of genomes to make gene-clusters based on nucleotide or amino acid content. Gene-clusters that contain genes from which every genome has at least one copy represent core functions of the microbes being compared. These could represent house-keeping genes and functions that are related to the central dogma. On the other hand, gene-clusters that are not shared by all genomes are called accessory gene-clusters and are unique to subsets of genomes. The accessory gene-clusters are a great source of potential fitness determining genes because they may help with niche partitioning of strains from different environments. This method is being utilized today to detect inter-strain variation (Maistrenko et al. 2020; Van Rossum et al. 2020) as well as detect regions of horizontal gene transfer and genomic islands (Bazin et al. 2020). Additionally, pangenomics can highlight disconnects between genomes who may look related phylogenomically (based on single-copy core genes) but in terms of gene content are quite different (Delmont and Eren 2018).
Pangenomes are a great way to learn about the core and accessory functions of closely related microbial populations by utilizing gene-clusters. On the other hand, metagenomic read recruitment allows one to ask ecological questions about the detection of specific microbes across samples. For example, one could investigate if a microbial population is a generalist (found in a lot of samples) or specialist (found in a few samples often in high abundance) by looking at the distribution of detection across a transect of the ocean. This combination of metagenomics and pangenomics is called metapangenomics (Delmont and Eren 2018) and the integration of the two approaches allows for the study of niche partitioning on a gene-clusters basis.
While pangenomics can reveal core genes that are shared between members of a population, it cannot be assumed that they are also environmentally relevant. As mentioned earlier in this post, there are numerous biases to isolating genomes (Great Plate Count Anomaly) and extracting MAGs from metagenomes. Stein et al. 1996 was inspired by the ubiquitous ecological signal from 16S distributions of Crenarcheota leading him to extract genomic contigs and infer novel metabolic pathways of Archaea in the ocean. Similarly, metapangenomics can highlight core genes lacking read recruitment from metagenomes which could indicate that there is maintained sequence diversity from adaptive evolution in natural populations (Delmont and Eren 2018). Moreover, accessory genes that consistently recruit reads from metagenomes could infer that there is a culturing bias and the genomes available do not represent ecological relevant population functional capacity. In essence, metapangenomics can confirm fitness determining genes in naturally occurring microbial populations.
Metapangenomics had yielded new biological insights that would not have been possible without this form of data integration. Delmont and Eren 2018 showed how Prochlorococcus strains not only had different sets of core genes specific to different photic zones, but also demonstrated that gene-clusters related to sugar metabolism are selected to have high sequence diversity. Reveillaud et al. 2019 found novel viral diversity in Wolbachia MAGs from insect ovaries via differential gene-cluster read recruitment. Additionally, Utter et al. 2020 demonstrated niche partitioning of H. parainfluenzae in the oral cavity by detecting different relative abundances of gene-clusters. All of these discoveries would not have been possible without the integration of evolution (pangenomics) and ecological (metagenomics) approaches.
Over and out…
My dive into the history of metagenomics has given me a great appreciation for the development of the field and the pioneers who creatively solved problems by developing new ways to analyze environmental metagenomic data. It seems like everyday the microbiome is being implicated in a new health or geologic process. Metagenomics has the potential to bolster hypothesis generation for these fields. I am very excited to be involved in a dynamic, multi-disciplinary field. Where else could I simultaneously study the ocean and human gut? Looking forward, I am most excited about how we will be able to ask high resolution questions about strain variation and protein sequence evolution. What will be Metagenomics 4.0? Let’s see if long-read sequencing can give us the 40kb genomic fragments the Stein et al. 1996 sequenced!