



Table of Contents
There is no clear “take home message” in this post. But if you are in the mood for some serious procrastination, please go ahead and read it at your own risk. You will find some insights into a metagenomic dataset, and at the end you may end up finding yourself inspired to look into the details of your own metagenomes in similar ways.
The reason there is no clear take home message is probably because even the simplest meatgenome is too complex to make complete sense of it. This is partially due to the complexity of microbial life really, but the rest of it is just the noise and bias we introduce way before we start seeing figures from our data. Even a single thread of questioning that involves a fraction of the picture can go too deep to reach its end in a reasonable amount of time and effort. I think that’s what happened here as well, and I believe this post will provide a glimpse into that, too.
I always see people who write well start their pieces with an insightful and fitting quote from an inspirational person. So here is mine:
No one will read your stupid blog post, and you are wasting your time with this data, Meren.
Background
Everything started when this paper appeared in Nature:
The story is quite a fascinating one even if you are not a microbiologist, and the claim is pretty grand. So clearly we wanted to take a look at the data .. you know, for the sake of science. However, it quickly became clear that the authors did not make any of the raw data available. This is a very disturbing issue that I keep running into. Think about how many people a study has to pass without any raw data before it gets published in a journal. I vocalized my frustration without expecting anything in return:
I can't believe there is no raw data for the complete nitrification paper. @Nature, how do your reviewers even review these submissions?
— A. Murat Eren (@merenbey) November 27, 2015But in return, I heard from Michael Wagner, the senior and corresponding author of another study on the same subject with a very similar title, which was even to appear in the same issue of Nature:
Wagner’s group did report the raw data, as well as the genome they recovered from their enrichments. It should be the standard, but unfortunately it is almost a surprise to see science being done the way it is supposed to.
A word for editors and reviewers
Before I continue with the data, I would like to have a monologue with all the confused editors and reviewers out there who forgot that science is all about reproducibility.

If you are an editor, and don’t see a “data availability” section in a manuscript, do science a favor and don’t send it out for review. If you are a reviewer who is asked to review a paper without any reported raw data, don’t review it, and send back an immediate correspondence to the editor to remind them that what they sent out for review is better classified as fiction in its current form. Yes, you may not have the time, the expertise, or the interest to go through all the data to make sure the critical claims in the manuscript are safe and sound. But if you at least pursue the authors to make their raw data available together with their manuscript, the community can identify if there is an outstanding problem. Here is a paper that was not properly reviewed, and here is a review that was done by the community to fix the error. So this really works when you don’t shoot us in the foot by not making sure the raw data is published.
So, do your job.
OK.
The study done by Wagner’s group is a very elaborate one. If you have read the paper, this post probably will make more sense to you, but if you didn’t, here is a quick and unfair recap of what they did:
- They sampled a microbial biofilm from a pipe used in a deep oil exploration well.
- They incubated the sample in specific conditions to enrich the ammonia-oxidizing microbes.
- After a series of subcultivation steps, they obtained ‘ENR4’, an enrichment culture that oxidizes ammonia to nitrate with lots of Nitrospira without any other detectable nitrifiers, plus multiple other bacterial populations.
- After more subcultivation steps, they obtained ‘ENR6’, which also oxidizes ammonia to nitrate, and in contrast to ‘ENR4’, this one contains only Nitrospira and one other bacterial population. These enrichment steps took 4 years!
- Thanks to the overall simplicity of these communities, deep sequencing, and the critical use of MinION, they recovered the complete genome of a Nitrospira population, and they named it -quite thoughtfully- “Candidatus Nitrospira inopinata”.
- And they characterized the key nitrification loci in this genome:

Overall, there is nothing alarming with their analyses, and if you are one of those skeptics and looking for external validation, please feel free to add my 2 cents into the the list of people who are pleased with this study.
That being said, there are some interesting things about this genome that puzzled me.
In the following sections I will write about my journey in this dataset while I will point out things that I couldn’t fully answer. As I will jump from one random thing to another, I hope the reader will be inspired by the potential uses of the platform we are working on, and see how easily one can go after challenging questions with it. If you don’t have much experience with metagenomes, you may also appreciate the challenges of working with metagenomic data (especially if you want to be meticulous).
I used the v2 clade of anvi’o for all these analyses, which is not available as a stable distribution yet, but you still can install it through our github repository following the installation instructions for “semi-pro” mode. You can find the essential anvi’o files here if you would like to reproduce any of the command lines in this text. For instance you can start with this one, which will start the interactive anvi’o environment:
$ anvi-interactive -p PROFILE.db -c CONTIGS.db --state state
A quick look at the assembled Nitrospira genome
Briefly, we downloaded the raw metagenomic data for three samples for ENR4 enrichment, and one sample for ENR6 enrichment, and using Bowtie2 with default parameters, we mapped the short reads back to the Candidatus Nitrospira inopinata genome (which will be shamelessly called “Wagner’s Nitrospira” in my figures, for which I apologize .. when I first started this I didn’t think I’d be writing about it).
In general the first thing we do after profiling and merging multiple metagenomic samples using anvi’o is to look at the “detection” view to see whether there are any segments that are not covered in any of the environments. Nothing surprising here as the entirety of the genome is covered in all four samples completely:
Each bar in the following figures represents a 2,000 nt long split from the genome.
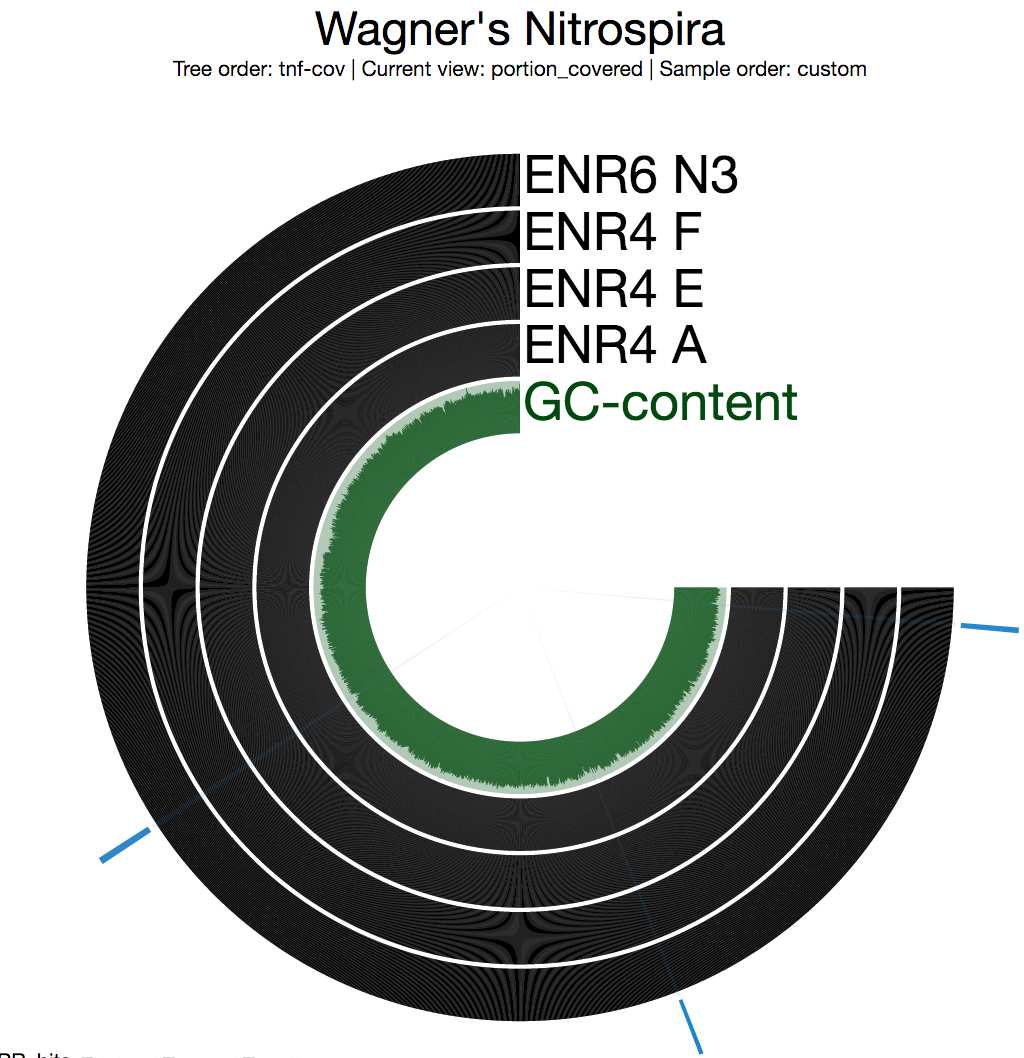
Blue selections indicate the three loci that are key for nitrification. If you go clockwise, they correspond to hao, nxr, and amo, respectively (see the loci figure above).
The second thing we generally do is to take a look at the mean coverage of each split:
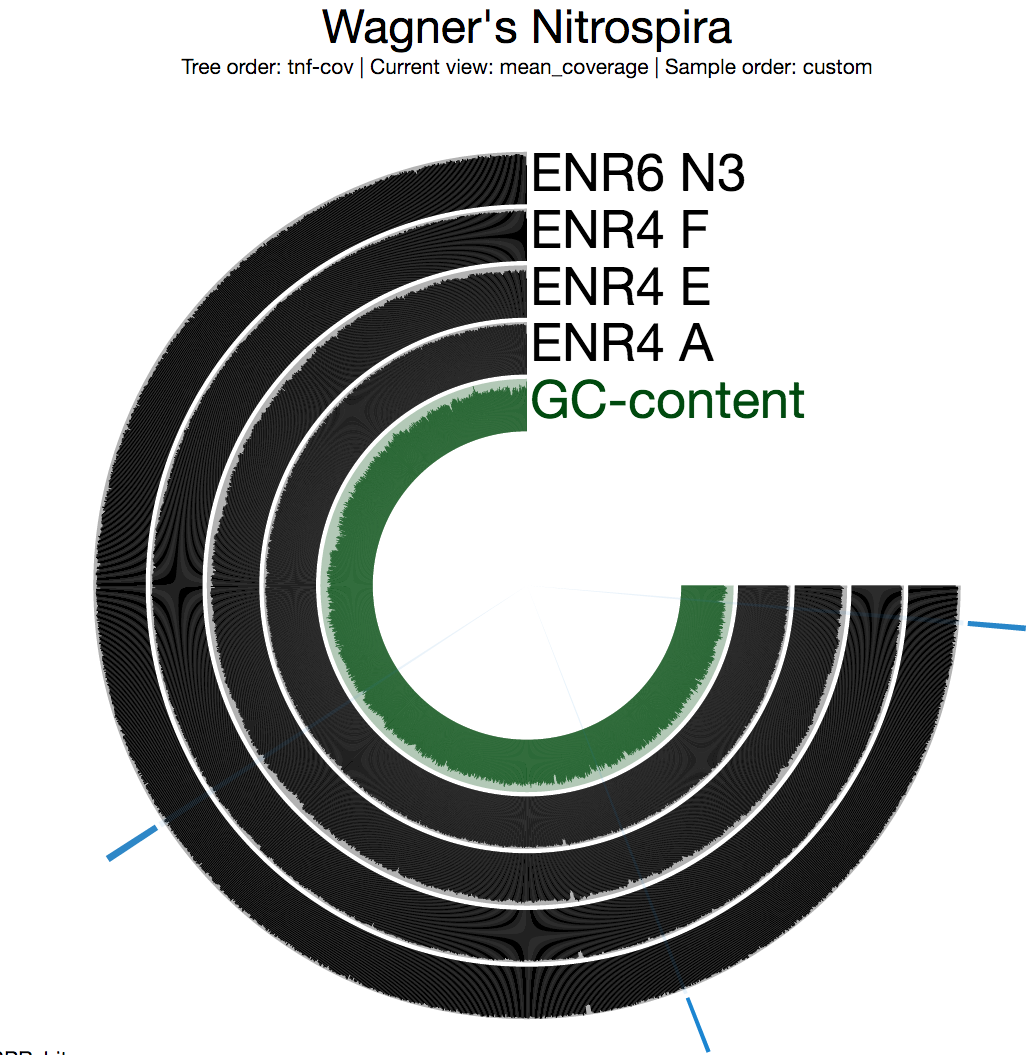
Among multiple sections with inconsistent coverage across the genome, one is pretty striking. But before going into the details of that section, I want to see a better view of inconsistent coverage to identify parts that really stick out. The standard deviation around coverage view is perfect for this:
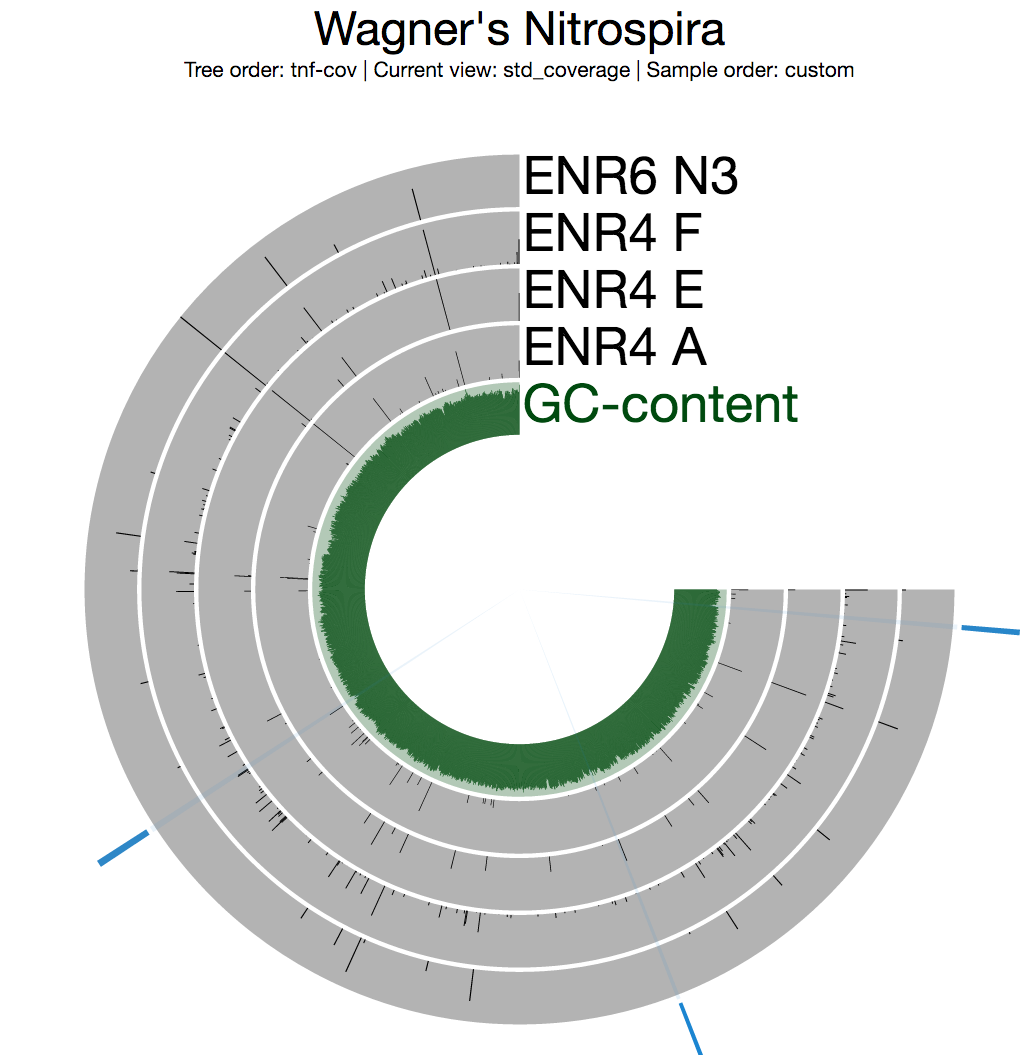
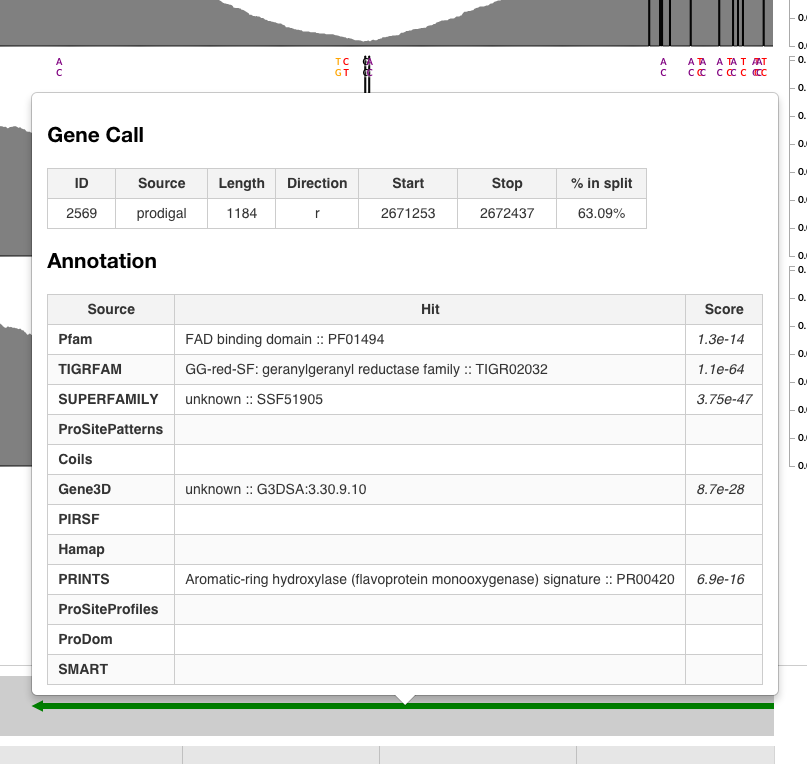
Inspecting the split with the highest standard deviation (the one around 10:30 o’clock in the figure above) shows some evidence for potentially faulty assembly since this is not something you expect to see from a circular / complete genome:
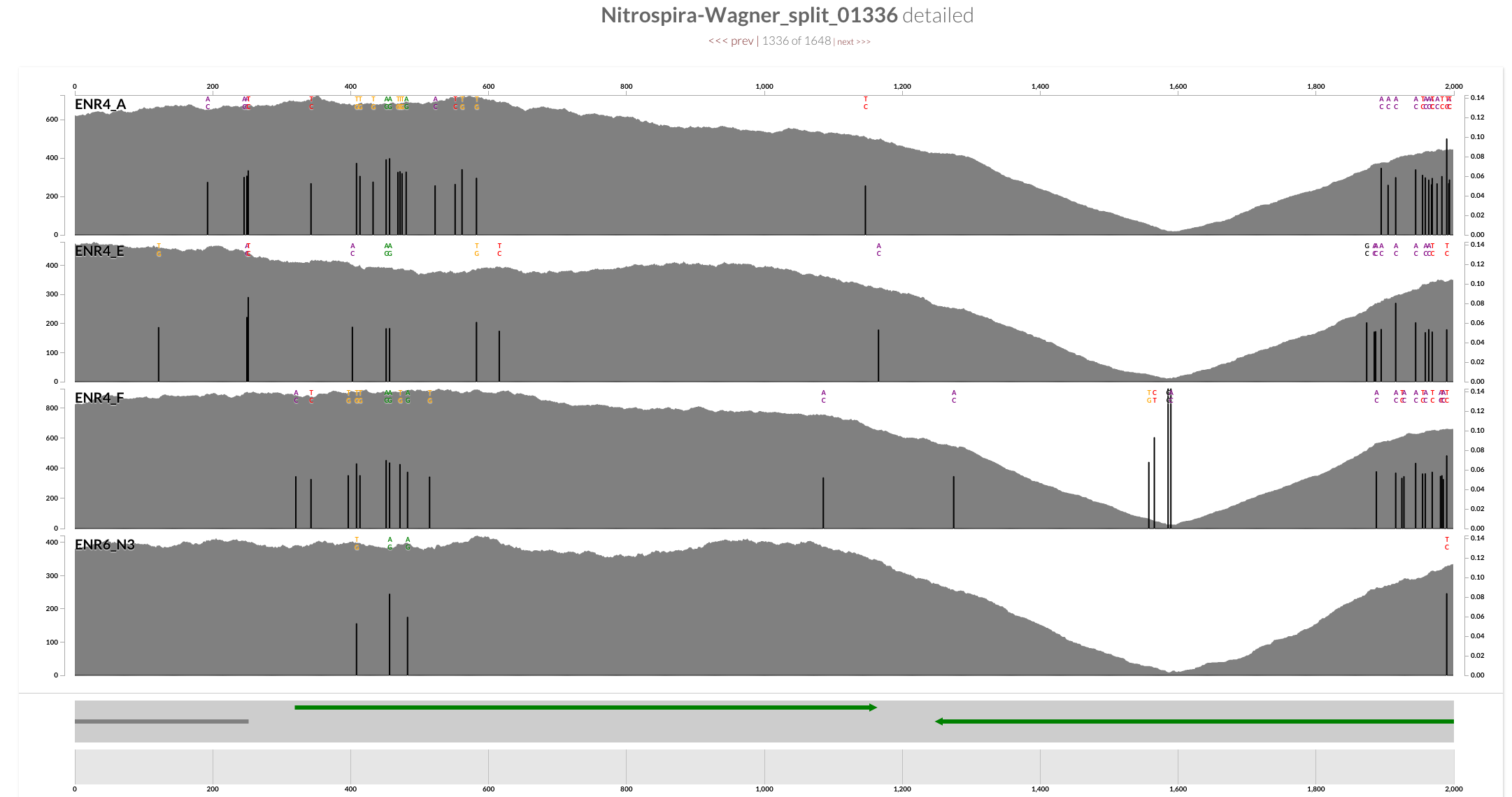
One explanation for this drop could be two contigs that are put together when they shouldn’t have been put together. On the other hand the gene caller identifies a gene that goes right across this region with some functional annotation, too. Puzzling.
{kind=link}
- [Computer scientist] Well, in a universe of endless possibilities, I really can't see why not the connecting ends of a chimeric contig happen to resolve to a proper gene.
- [Microbiologist] Because it can't ... and you know, it is not really 'science'.
- [Computer guy] :(((
And the gene is not a chimeric one: A BLAST search of this gene as it appears in the genome returns many hits on NCBI.
The top one is this with 100% identity, which is not surprising, but very cute regardless, as it shows that stuff people built, does work.
The other two in the top three are this one and this one with 60%+ identity and 90%+ query coverage for both! Both of these hits are coming from enrichments done by the other group –who did not publish their raw data, and therefore shall not be mentioned here any further.
So yes, this gene is not chimeric, but according to the mapping, there is something weird going on with it. This is not a unique example, and the presence of these sudden drops in coverage may be suggesting that the genome needs more work to be considered “final final”. Although, it may also be the case that this genome is already the best genome that could be generated from this dataset.
I also did an alternative assembly: I took all short reads from the three ENR4 samples, and one ENR6 sample, trimmed them to 150nts to avoid poor quality ends of both reads in each pair, and co-assembled them using MEGAHIT. Then I BLAST’ed each split in Wagner’s Nitrospira genome against the resulting contigs from the assembly. Then I wrote a Python script to make sense of the BLAST result. A total of 2,187,422 nts from the assembly matched to the Nitrospira final genome. In other words, my assembly of their data recovered about 66% of the Ca. N. inopinata genome. And the average nucleotide identity between the matching 66% was 98.9%. It is normal that my assembly recovered only two-thirds of the genome since I didn’t use longer reads as Wagner’s group did, but the difference in nucleotide identity was surprising to me. On the other hand, although I am not sure which assembly is less right, 1% divergence may not be too concerning. I simply don’t know.
OK, enough of this. Let’s finally take a look from the variability view, which shows the summary of the density of variation at each nucleotide position for each split based on mapped short reads:

This is getting interesting! There are multiple regions in the genome that shows remarkable variation when short reads are mapped back. According to our experience, these regions often indicate heterogeneity in the source community, and we really like them as they have the potential to provide deeper insights into the ecology we are going after (and sometimes they are there as by products of bad assembly, or bad mapping). The true power of metagenomics come from co-assemblies and understanding community heterogeneity through these often-quite-subtle variations.
One of the highly variable regions across the genome overlap with the region that showed remarkable decrease in the mean coverage we saw in the mean coverage view:

A quick inspection indicates the presence of CRISPR-associated proteins, so I decide to highlight all CRISPR-associated genes on this view. I go back to my terminal, and type this to search for all functions that contains the term “CRISPR”:
$ anvi-search-functions-in-splits -c CONTIGS.db \
-o CRISPR-SPLITS.txt \
--verbose \
--search CRISPR
Contigs DB ...................................: Initialized: CONTIGS.db (v. 4)
Search terms .................................: 1 found
Matches ......................................: 25 unique gene calls contained the search term "CRISPR"
Matching names for 'CRISPR' (up to 25)
===============================================
cas4: CRISPR-associated protein Cas4
cas_Csd2: CRISPR-associated protein Cas7/Csd2, subtype I-C/DVULG
cas_Csd1: CRISPR-associated protein Cas8c/Csd1, subtype I-C/DVULG
cas5_6_GSU0054: CRISPR-associated protein GSU0054/csb2, Dpsyc system
CRISPR-associated protein NE0113 (Cas_NE0113)
CRISPR_cas5: CRISPR-associated protein Cas5
cas1: CRISPR-associated endonuclease Cas1
cas1_DVULG: CRISPR-associated endonuclease Cas1, subtype I-C/DVULG
cas7_GSU0053: CRISPR-associated protein GSU0053/csb1, Dpsyc system
CRISPR-associated protein (Cas_Cmr5)
cas_Cas5d: CRISPR-associated protein Cas5, subtype I-C/DVULG
cas2: CRISPR-associated endonuclease Cas2
CRISPR-associated protein, GSU0054 family (Cas_GSU0054)
cas3_HD: CRISPR-associated endonuclease Cas3-HD
TIGR02710: CRISPR-associated protein, TIGR02710 family
cas3_GSU0051: CRISPR-associated helicase Cas3, subtype Dpsyc
CRISPR associated protein Cas2
CRISPR associated protein Cas1
CRISPR-associated protein (Cas_Cmr3)
cas_CT1132: CRISPR-associated protein, CT1132 family
cas_RAMP_Cmr4: CRISPR type III-B/RAMP module RAMP protein Cmr4
CRISPR-associated protein (Cas_APE2256)
cas_Cmr5: CRISPR type III-B/RAMP module-associated protein Cmr5
TIGR02619: putative CRISPR-associated protein, APE2256 family
CRISPR-associated protein (Cas_Csd1)
Additional metadata compatible output ........: CRISPR-SPLITS.txt
This search generates a matrix file that shows where are all these CRISPR-associeated genes. I restart the interactive interface with this additional information:
$ anvi-interactive -p PROFILE.db -c CONTIGS.db -A CRISPR-SPLITS.txt
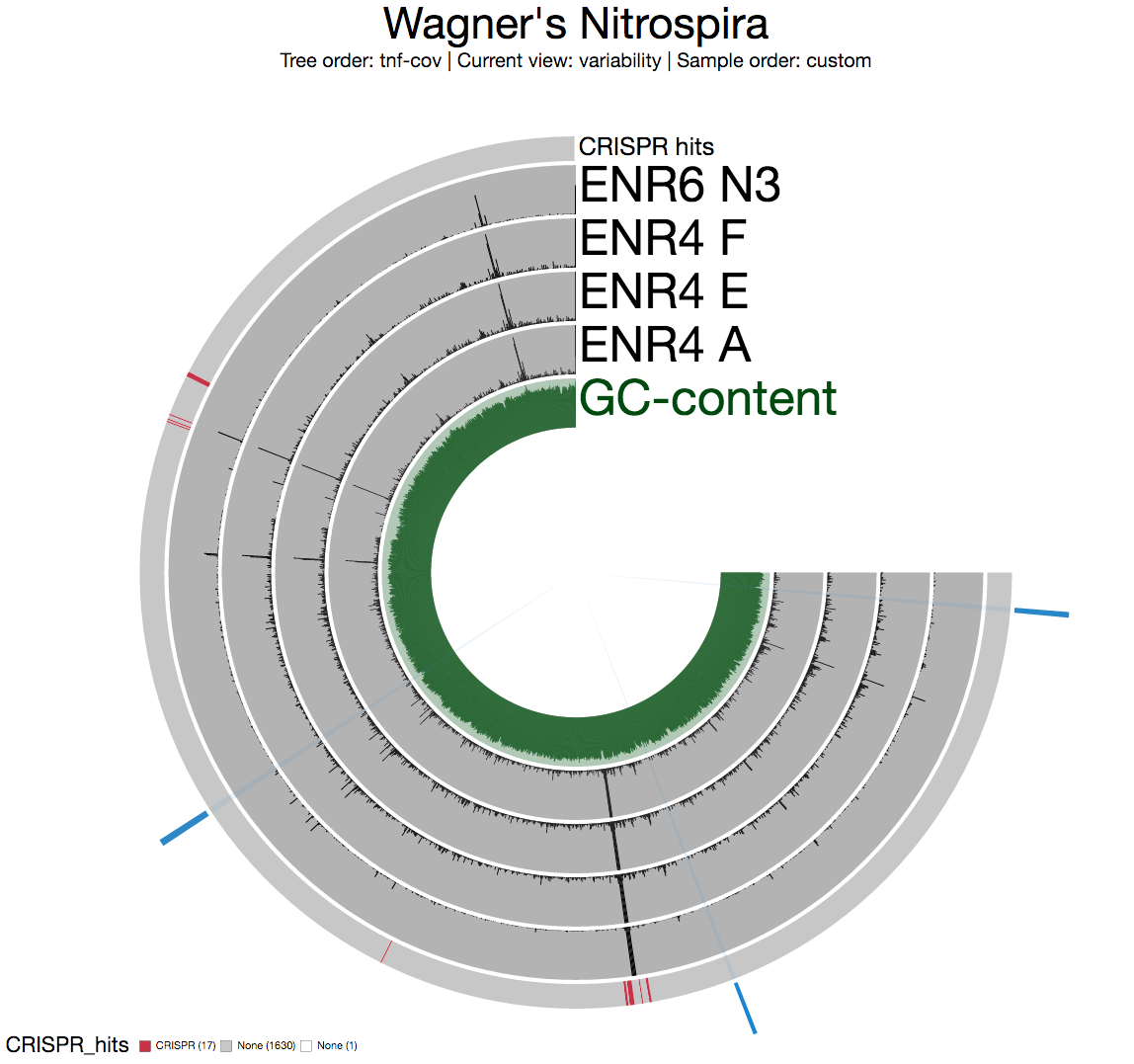
Now we have an extra layer in all anvi’o views for splits with CRISPR hits. Not every occurrence of a CRISPR-associated protein indicates a locus, but it seems there are two clusters of CRISPR-associated proteins right around a very highly variable region. This is what inspection shows for a split right in the middle of the most variable region:
This view is probably not very surprising to people who study CRISPRs. Seeing the tremendous amount of diversity within the spacer / repeat region that follow Cas operons even within a rather homogeneous population of Nitrospira coming from an enrichment is still striking to me. It is a mess, but fortunately not a random one either; usually competing nucleotide identities at variable positions match across four samples:

Breaking news: CRISPRs break your contigs …
I also took multiple short reads Bowtie2 mapped to this crazy variable region, and BLASTed them against the genome. The result was quite scary: each read was broken into multiple alignments, and aligned to slightly different parts of this repeat region. This is exactly why your de brujin graph resolving assembler using short reads will never be able to recover itself from seeing a CRISPR region, and will end up braking up your contigs during the reconstruction. Wagner’s group overcame this limitation of the assembly by using MinION reads.
While looking at this data I also realized that every CRISPR-associated protein I find in a contig collection from any metagenomic assembly should be at the very end of contigs in which they are identified. Of course repeats in CRISPR spacer region is only one of the issues that fragment our otherwise beautiful contigs, but it is something that is easier to test since the spacer region follows the well-described Cas operons we can look for. I took one of the assemblies Tom created from an ocean sample, and searched for CRISPR-associated proteins, and look what I’ve found:
| Contig | Contig length | Gene name | Gene start | Gene end |
|---|---|---|---|---|
| contig_x | 5305 | CRISPR-associated protein, Csy3 family | 3319 | 4323 |
| contig_y | 3416 | CRISPR-associated protein, Cse1 family | 2608 | 3396 |
| contig_z | 306597 | CRISPR-associated protein Cas1 | 303304 | 303714 |
| contig_t | 5600 | CRISPR-associated helicase Cas3 | 3952 | 5334 |
| contig_n | 12451 | CRISPR-associated protein, Csd1 family | 12064 | 12393 |
They are truly towards the end of each contig. Scars of a nightmare the assembler run into.
What if we tried a different mapping software?
The two screenshots from the CRISPR region is clearly concerning. That shows how many mismatches Bowtie2 allows by its default parameters. Just to see whether the story changes at all, I mapped all short reads from ENR4-A back to the genome using both Bowtie2 and BWA (aln and mem), and by using multiple values for number of mismatches allowed for aln (via n) and different seed lengths for mem (via K). The overall pattern of variability within these genomes did not change:
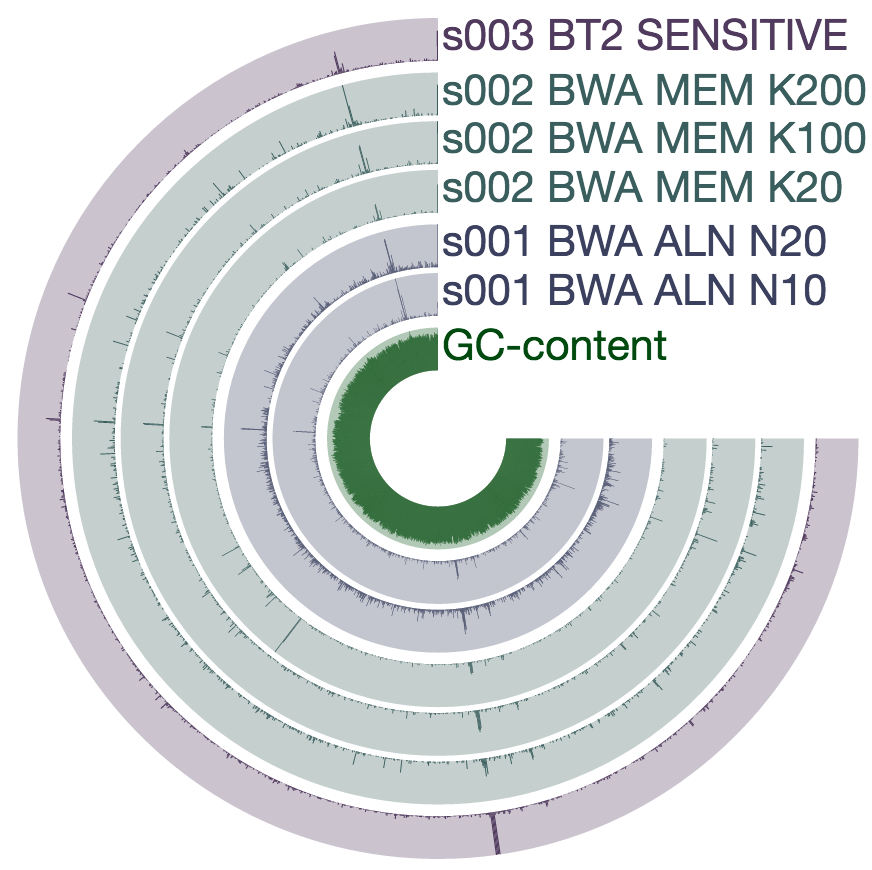
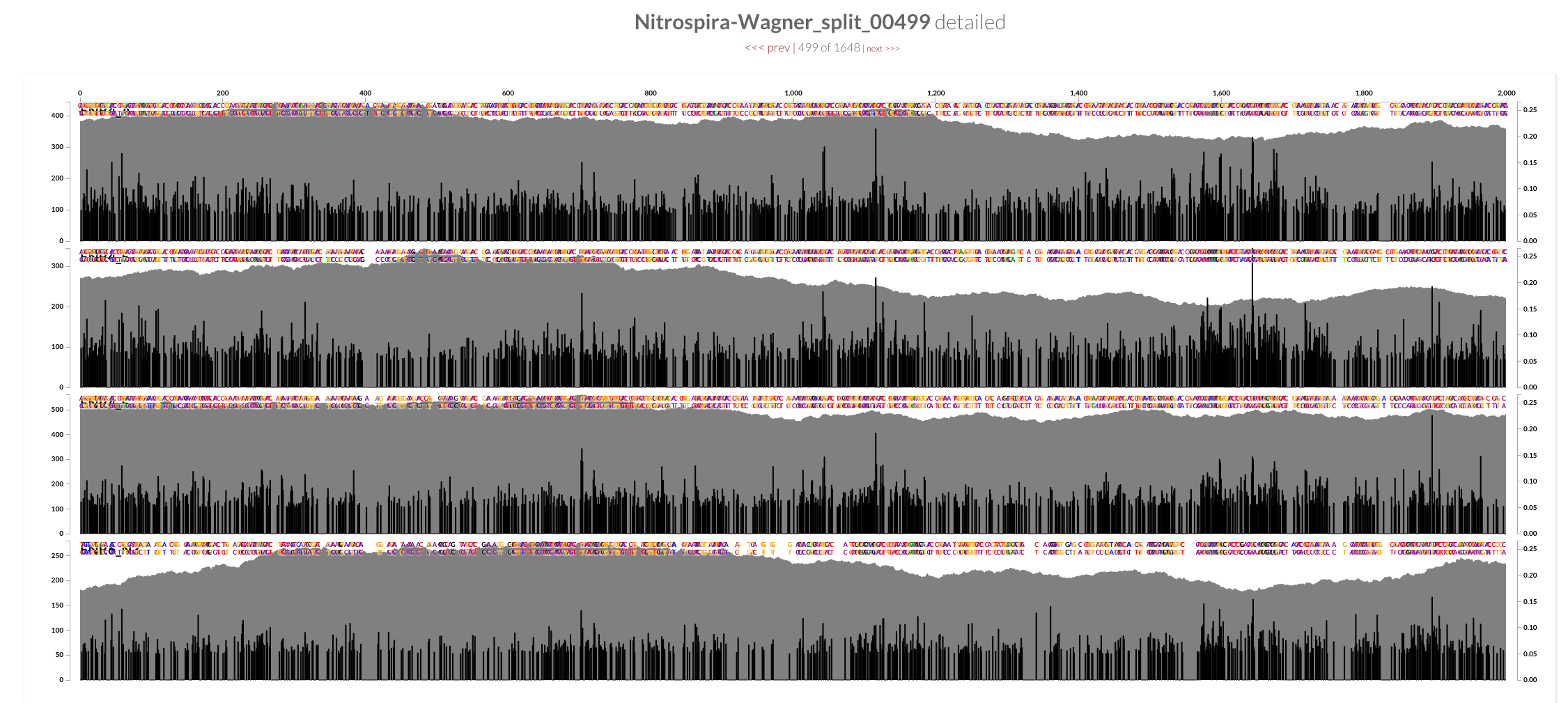
However, the mean coverage for highly-variable splits did change from one mapping to another. For instance, this is how these different mapping software compare to each other at the variable region in split 499 (see the figure above):
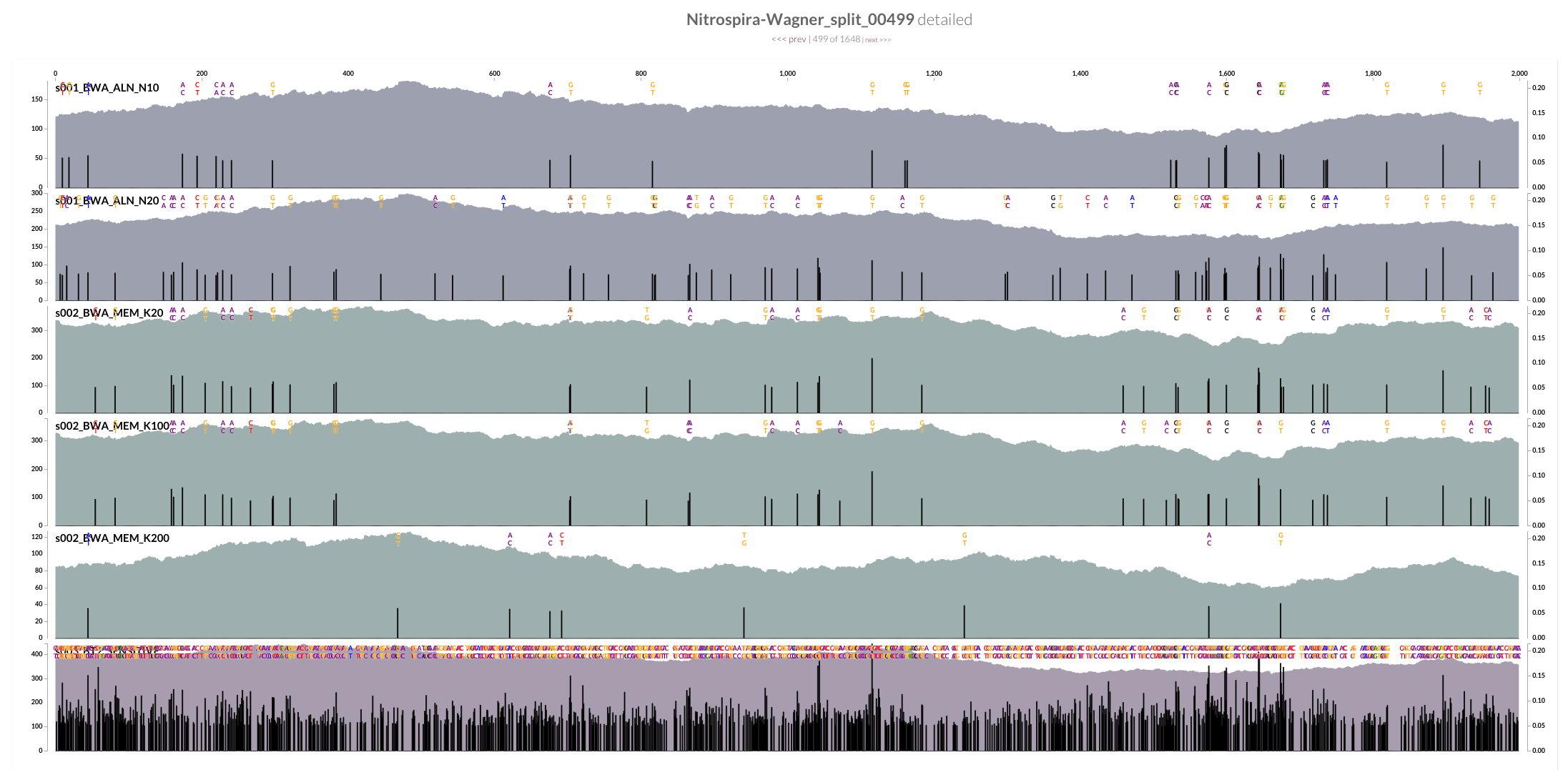
Bowtie2 does a great job mapping anything and everything to the best context it can find. But when I made mapping a bit more stringent by playing BWA’s parameters, a sharp decline in coverage in the spacer / repeat region has emerged. Here, it is much more clear at the very beginning of the spacer / split region, right after Cas operons:
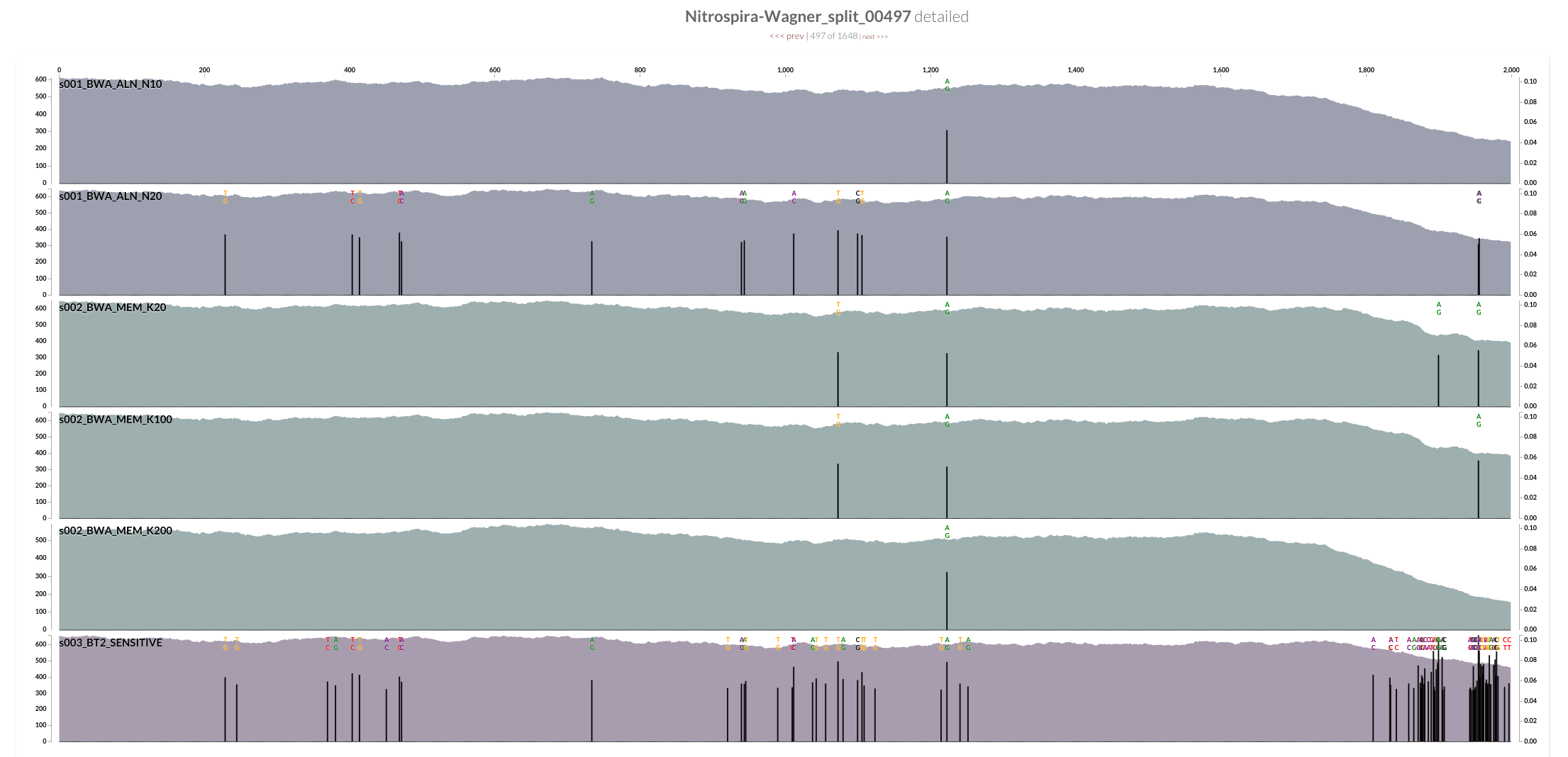
While the coverage with BWA MEM K200 drops almost 70%, it only drops about 20% with Bowtie2. The reads Bowtie2 manage to map indeed results in lots and lots of variable positions due to non-specific mapping.
A likely reason for non-specific mapping
The reason for occasional non-specific mapping and/or dramatic shift in coverage is partly/likely because Candidatus Nitrospira inopinata is a consensus genome. When you look at those regions with decreased coverage, it is not the case that those reads that are not mapping to those regions, go somewhere else in the genome to counterbalance the drop. This can only be due to heterogeneity in the Nitrospira community. Because even if in fact the assembly is not perfect, there still are some reads that are mapping to it nicely, and some that are not mapping to it the same way. It is also important to note that there are only drops in this otherwise quite stably-covered genome. I think this particular scenario takes place in situations like enrichments: there is a very dominant population of very similar genomes, from which reads can only escape (when they don’t agree with the consensus). In more complex datasets we often observe non-specific mapping that include bumps in coverages as well.
In the best-case scenario (and the one I’d put my money on) the assembly of Candidatus Nitrospira inopinata has no chimeric genes anywhere, and it accurately represents at least one member of the Nitrospira community. This probably is either very clear right off the bat, or makes a lot of sense to microbiologists, and to people who spent lots of time thinking about bacterial evolution. But as someone who recently transferred from the marker gene world, these are all surprising to me if I’m not making a terrible job at making sense of what I’m seeing, and my take home message from these observations is two folds:
- We are seeing heterogeneity at this level of resolution in naturally occurring populations thanks to metagenomics.
- Maybe we should be more skeptical of our convictions based on marker genes alone.
We looked at the microbial world using 3% OTUs and were surprised and confused about the diversity of bacteria. But I am starting to believe that there isn’t even a meaningful unit to really discuss about the real diversity of the microbial world.
OK. Back to the topic. So, I’ll just assume Candidatus Nitrospira inopinata is a consensus genome, and when almost all members of this community agrees with the most nucleotide information that’s making up this genome, there are certain parts they disagree, hence the drop in coverage, or increase in variable positions. Remember that this is an enrichment study, and represents a very simple metagenome, yet here we are, dealing with changes in coverage or increase in variable positions in mapping results whether due to community heterogeneity or imperfections in assembly. How are we even supposed to rely on mapping results to study metagenomes when even the simplest metagenome challenges us with so much to understand? I have no answer to this myself. But I’m almost convinced that although it is essential, mapping short reads back to contigs is quite a pitiful way to make sense of metagenomes. To characterize metagenomes properly, we need to take a step back and work with graph structures directly instead of contigs reported by assemblers.
The curious case of AmoC
Then I continued.
Decrease in the coverage around CRISPR operons is interesting, but I guess it is somewhat expected. On the other hand, a quick inspection of the ‘amo’ locus does show a clear decrease in the coverage of one of the genes in all four samples as well:
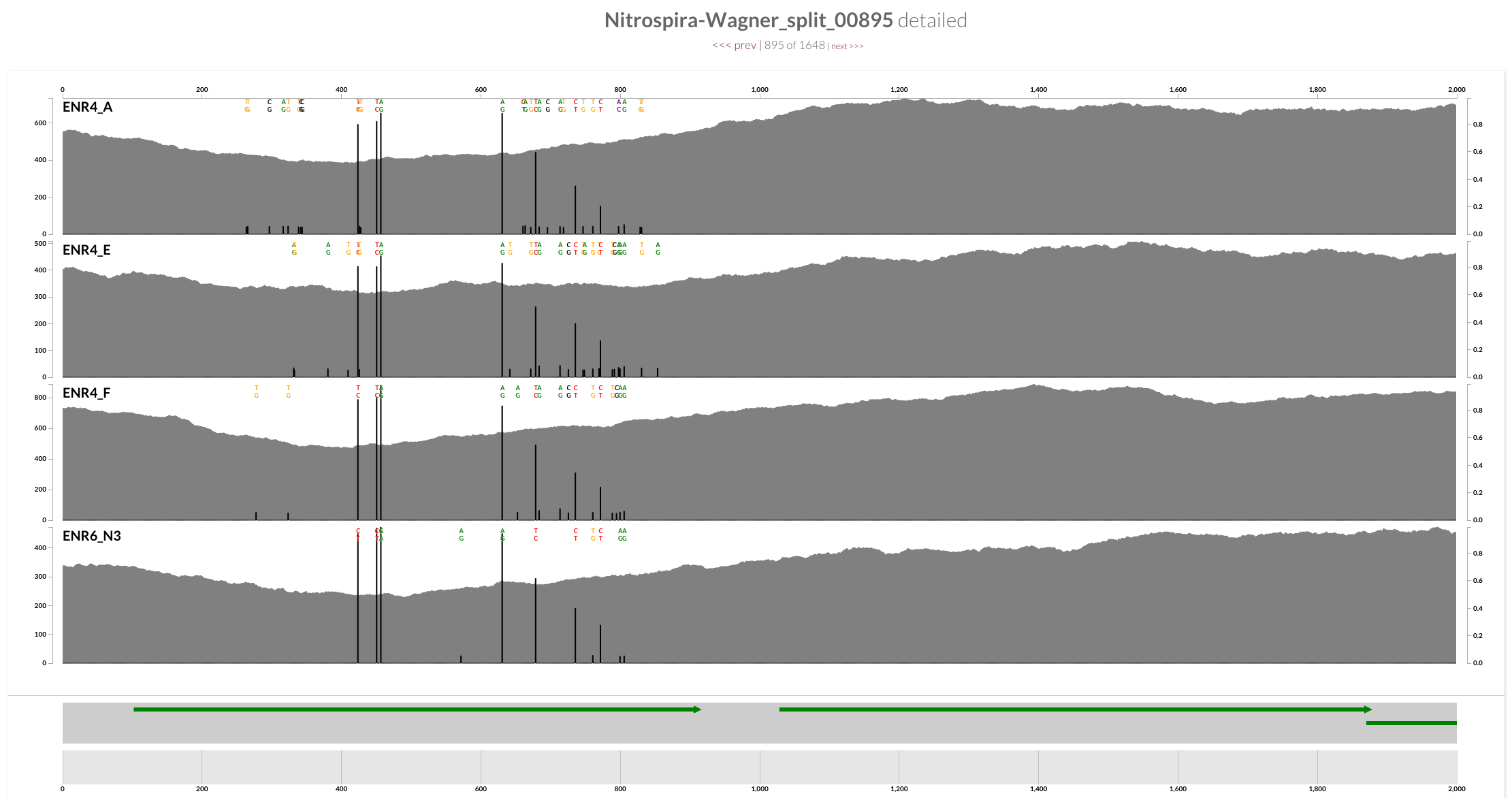
The annotation indicates that this gene is AmoC:
And mapping with BWA confirms the trend is not specific to Bowtie2:
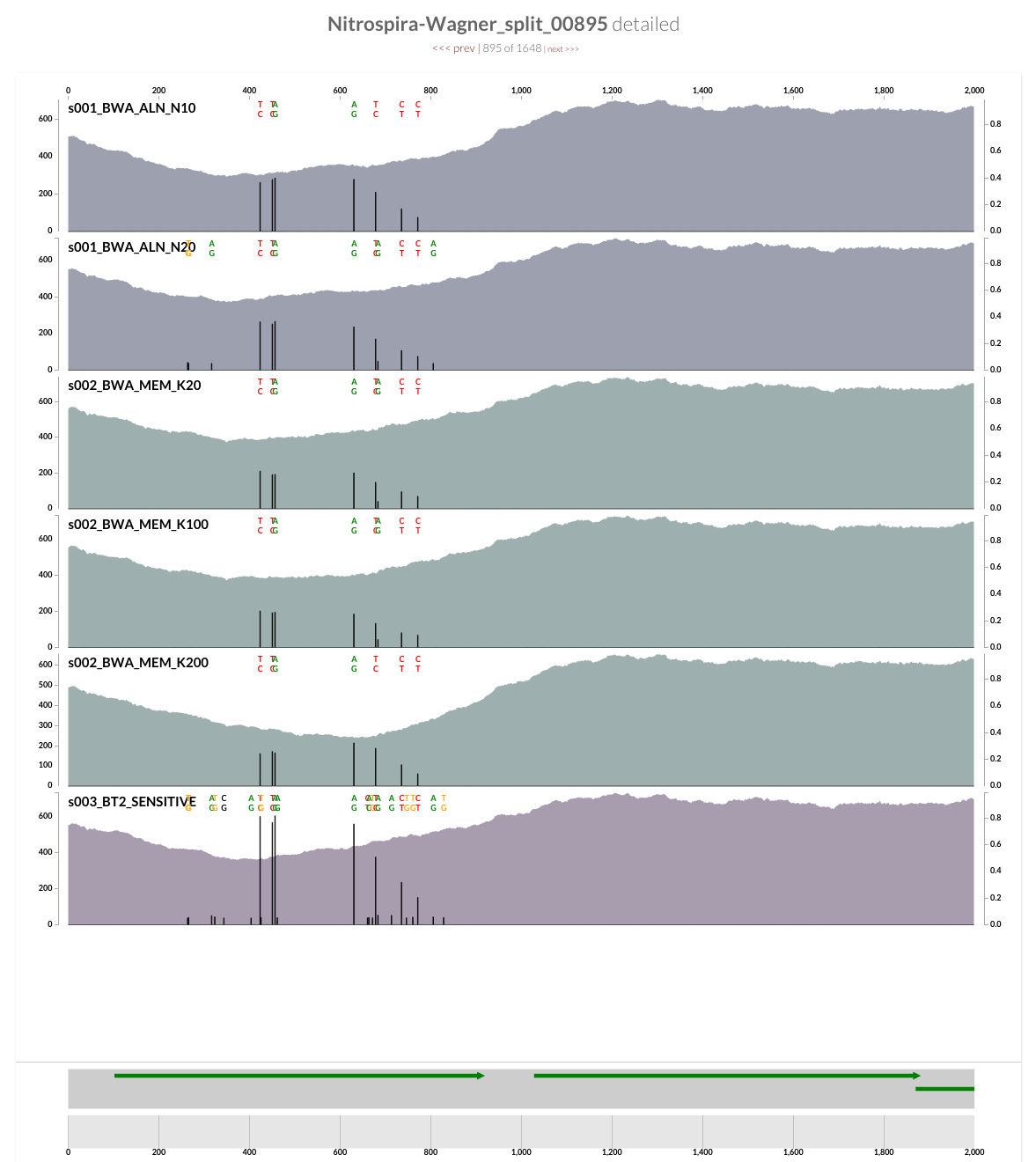
The paper mentions that there are three copies of this gene in the genome.
The critical question is this: Where did the reads that did not map here go? Could they have mapped to the context of other AmoCs?
To identify which regions of the genome I should be looking for those other copies, I did a quick search using anvi-search-functions-in-splits:
$ anvi-search-functions-in-splits -c CONTIGS.db \
--search-terms "CH4_NH3mon_ox_C" \
-o AmoC-hits.txt \
--delimiter '!' \
--full-report AmoC-report.txt
Contigs DB ...................................: Initialized: CONTIGS.db (v. 4)
Search terms .................................: 1 found
Matches ......................................: 3 unique gene calls contained the search term "CH4_NH3mon_ox_C"
Full report ..................................: AmoC-report.txt
Additional metadata compatible output ........: AmoC-hits.txt
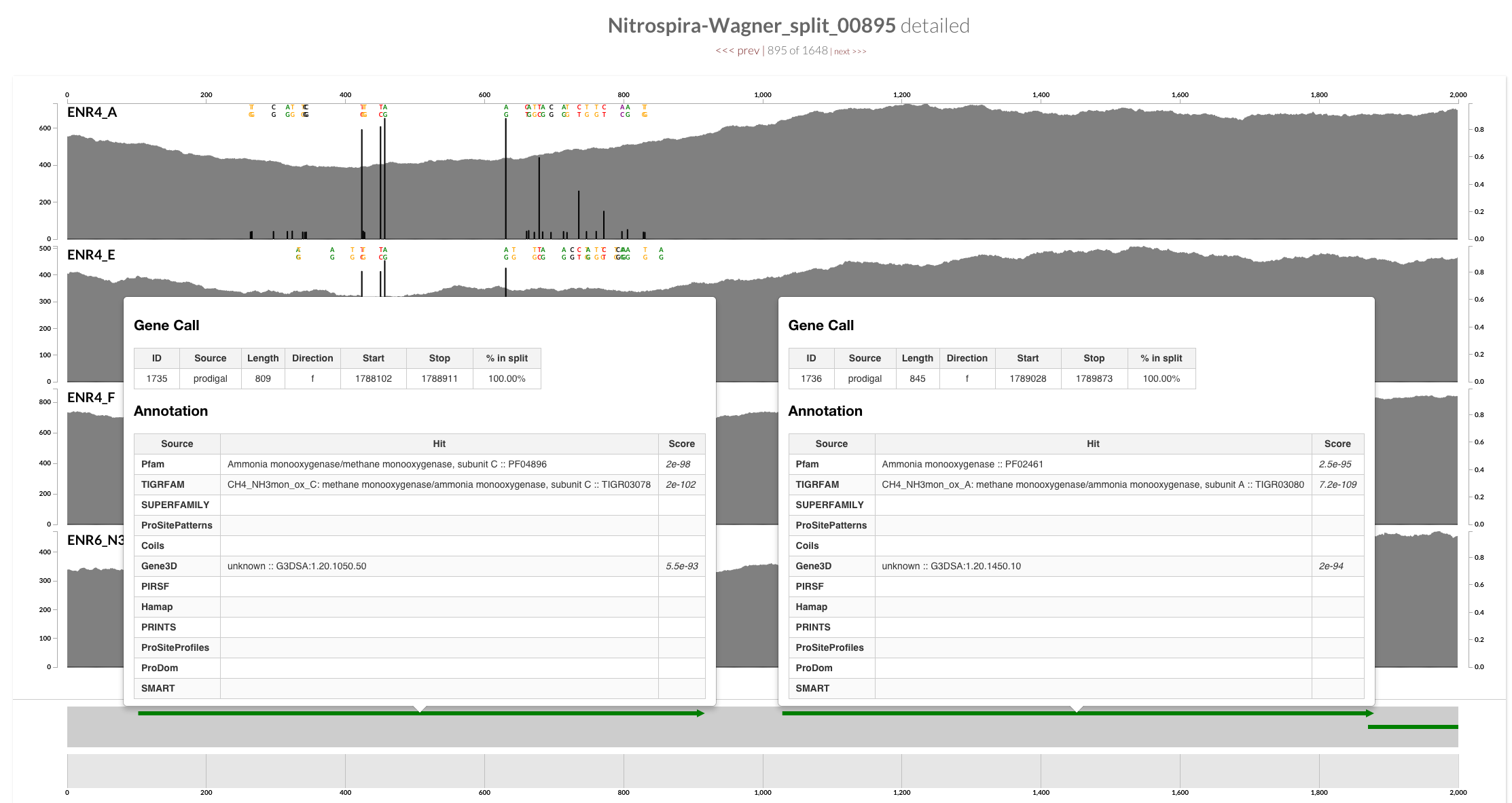
One of the output files, AmoC-report.txt shows the IDs of these three genes in the anvi’o contigs database for Candidatus Nitrospira inopinata, and split IDs that carry the gene:
| gene_callers_id | source | function | search_term | split_name |
|---|---|---|---|---|
| 709 | TIGRFAM | CH4_NH3mon_ox_C: methane monooxygenase/ammonia monooxygenase, subunit C | CH4_NH3mon_ox_C | Nitrospira-Wagner_split_00368 |
| 1735 | TIGRFAM | CH4_NH3mon_ox_C: methane monooxygenase/ammonia monooxygenase, subunit C | CH4_NH3mon_ox_C | Nitrospira-Wagner_split_00895 |
| 1184 | TIGRFAM | CH4_NH3mon_ox_C: methane monooxygenase/ammonia monooxygenase, subunit C | CH4_NH3mon_ox_C | Nitrospira-Wagner_split_00606 |
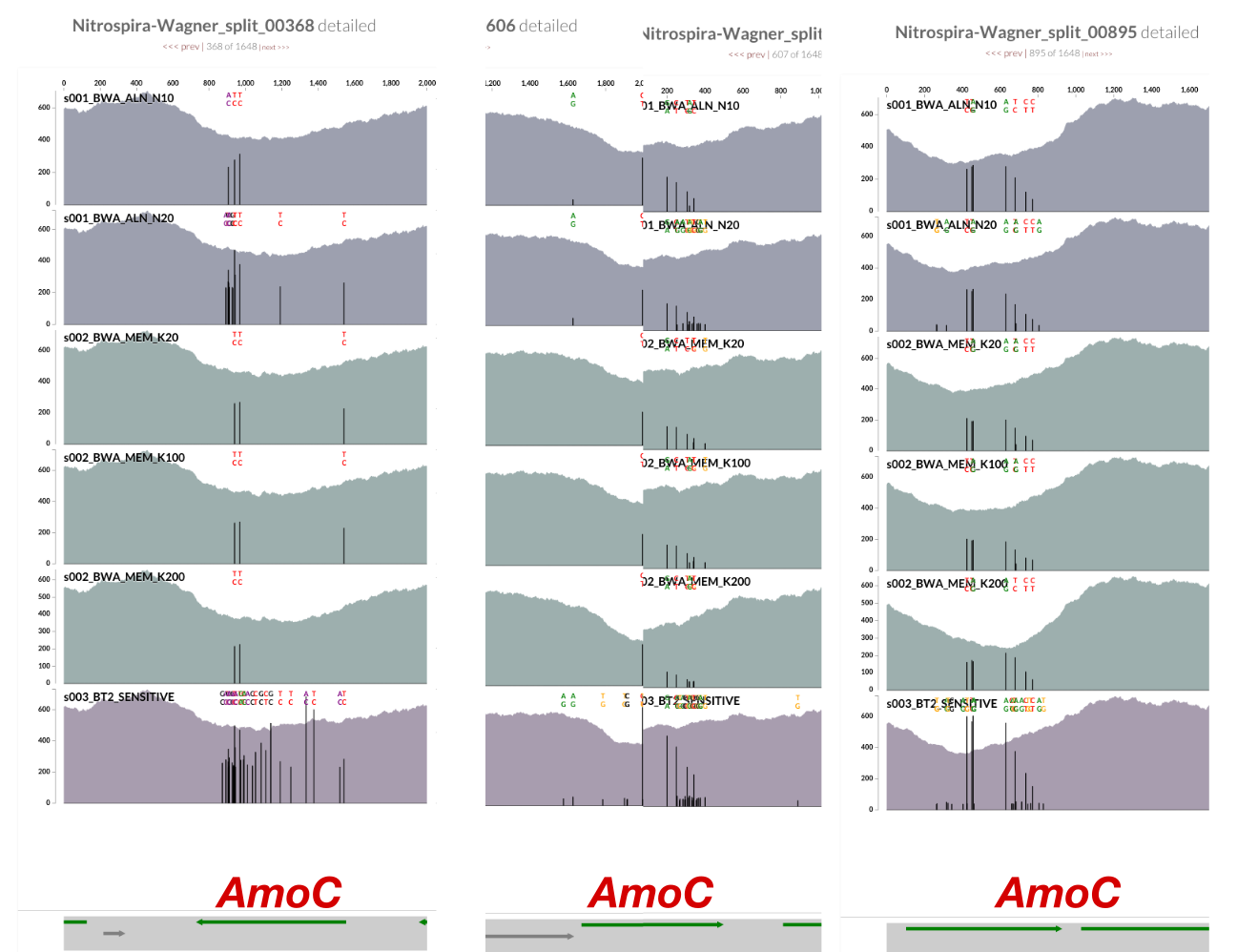
Inspecting splits 368, 606, and 895 showed that the drop in coverage for AmoC is common to all (sorry for the poor screenshot work for split 606, the gene was cut right in the middle, and the scales between the two splits differed):
To see which of the two are identical, I asked anvi’o to give me back the sequences for all these three AmoC genes from the genome:
$ anvi-get-dna-sequences-for-gene-calls -c CONTIGS.db \
-o AmoC-sequences.fa \
--gene-caller-ids 709,1735,1184 \
--wrap 0
Contigs DB ...................................: Initialized: CONTIGS.db (v. 4)
Output .......................................: AmoC-sequences.fa
The output file is a simple FASTA file:
>709|contig:Nitrospira-Wagner|start:734744|stop:735554|direction:r|rev_compd:True|length:810
ATGGCGGCAGAGCGGGGGTATGACATTTCGCAGTGGTATGATTCGCGGCCGTGGAAGATTGGGTGGTTTGCGATGTTGGCGATTGG (...)
>1735|contig:Nitrospira-Wagner|start:1788101|stop:1788911|direction:f|rev_compd:False|length:810
ATGGCGGCAGAGCGGGGCTATGACATTTCGCAGTGGTATGATTCGCGGCCGTGGAAGATTGGGTGGTTTGCGATGTTGGCGATTGG (...)
>1184|contig:Nitrospira-Wagner|start:1211671|stop:1212481|direction:f|rev_compd:False|length:810
ATGGCGGCAGAGCGGGGCTATGACATTTCGCAGTGGTATGATTCGCGGCCGTGGAAGATTGGGTGGTTTGCGATGTTGGCGATTGG (...)
Just to make sure we are on the right track, here is the alignment of all three:
CLUSTAL multiple sequence alignment by MUSCLE (3.8)
709|contig:Nitrospira-Wagner|sta ATGGCGGCAGAGCGGGGGTATGACATTTCGCAGTGGTATGATTCGCGGCCGTGGAAGATT
1184|contig:Nitrospira-Wagner|st ATGGCGGCAGAGCGGGGCTATGACATTTCGCAGTGGTATGATTCGCGGCCGTGGAAGATT
1735|contig:Nitrospira-Wagner|st ATGGCGGCAGAGCGGGGCTATGACATTTCGCAGTGGTATGATTCGCGGCCGTGGAAGATT
***************** ******************************************
709|contig:Nitrospira-Wagner|sta GGGTGGTTTGCGATGTTGGCGATTGGGATTTTTTGGGTGTTGTATCAGCGGACGTTTGGG
1184|contig:Nitrospira-Wagner|st GGGTGGTTTGCGATGTTGGCGATTGGGATTTTTTGGGTATTGTATCAGCGGACGTTTGGG
1735|contig:Nitrospira-Wagner|st GGGTGGTTTGCGATGTTGGCGATTGGGATTTTTTGGGTATTGTATCAGCGGACGTTTGGG
************************************** *********************
709|contig:Nitrospira-Wagner|sta TATTCGCACGGGTTGGACTCGATGACGCCGGAGTTTGACGCGGTGTGGATGGGGTTATGG
1184|contig:Nitrospira-Wagner|st TATTCGCACGGGTTGGACTCGATGACGCCGGAGTTTGACGCGGTGTGGATGGGGTTGTGG
1735|contig:Nitrospira-Wagner|st TATTCGCACGGGTTGGACTCGATGACGCCGGAGTTTGACGCGGTGTGGATGGGGTTGTGG
******************************************************** ***
709|contig:Nitrospira-Wagner|sta CGGTTTAACATTGTGGCCAATGCGTTATTTTTTGCGATTTCGGTGGGGTGGATTTGGGTG
1184|contig:Nitrospira-Wagner|st CGGTTTAACATTGTGGCCAATGCGTTATTTTTTGCGATTGCGGTGGGGTGGATTTGGGTG
1735|contig:Nitrospira-Wagner|st CGGTTTAACATTGTGGCCAATGCGTTATTTTTTGCGATTGCGGTGGGGTGGATTTGGGTG
*************************************** ********************
709|contig:Nitrospira-Wagner|sta ACGCGGGATCGGAATTTGGCGAATTTGGATCCGAAGACGGAGTTGAAGCGGTATTTTTAC
1184|contig:Nitrospira-Wagner|st ACGCGGGATCGGAATTTGGCGAATTTGGATCCGAAGACGGAGTTGAAGCGGTATTTTTAC
1735|contig:Nitrospira-Wagner|st ACGCGGGATCGGAATTTGGCGAATTTGGATCCGAAGACGGAGTTGAAGCGGTATTTTTAC
************************************************************
709|contig:Nitrospira-Wagner|sta TGGATGGGGTGGTTGGCCTGCTACGTGTGGGGGGTCTATTATGCGGGCAGCTACACGTTG
1184|contig:Nitrospira-Wagner|st TGGATGGGGTGGTTGGCCTGCTATGTGTGGGGGGTCTATTATGCGGGCAGTTACACATTG
1735|contig:Nitrospira-Wagner|st TGGATGGGGTGGTTGGCCTGCTATGTGTGGGGGGTCTATTATGCGGGCAGTTACACATTG
*********************** ************************** ***** ***
709|contig:Nitrospira-Wagner|sta GAGCAGGATGCGGCGTGGCATCAGGTGATCATTCGGGACACGAGTTTTACGGCCAGTCAC
1184|contig:Nitrospira-Wagner|st GAGCAGGATGCGGCGTGGCATCAGGTGATCATTCGGGACACGAGTTTTACGGCGAGTCAC
1735|contig:Nitrospira-Wagner|st GAGCAGGATGCGGCGTGGCATCAGGTGATCATTCGGGACACGAGTTTTACGGCGAGTCAC
***************************************************** ******
709|contig:Nitrospira-Wagner|sta ATTGTGGCGTTTTACGGGACGTTCCCGTTGTACATTACGTGCGGGGTCTCGAGTTATCTG
1184|contig:Nitrospira-Wagner|st ATTGTGGCGTTTTACGGGACATTCCCGTTGTACATTACGTGCGGGGTGTCGAGTTATCTG
1735|contig:Nitrospira-Wagner|st ATTGTGGCGTTTTACGGGACATTCCCGTTGTACATTACGTGCGGGGTGTCGAGTTATCTG
******************** ************************** ************
709|contig:Nitrospira-Wagner|sta TATGCGCAGACGCGGTTGCCGTTGTATAGCCAGGCGACGTCGTTTCCGTTGGTGGCGGCG
1184|contig:Nitrospira-Wagner|st TATGCGCAGACGCGGTTACCGTTGTATAGCCAGGCGACGTCGTTTCCGTTGGTGGCGGCG
1735|contig:Nitrospira-Wagner|st TATGCGCAGACGCGGTTACCGTTGTATAGCCAGGCGACGTCGTTTCCGTTGGTGGCGGCG
***************** ******************************************
709|contig:Nitrospira-Wagner|sta GTGGTGGGGCCGATGTTCATTTTGCCGAACGTGGGGCTCAATGAGTGGGGCCATGCGTTT
1184|contig:Nitrospira-Wagner|st GTGGTGGGGCCGATGTTCATCTTACCGAACGTGGGGCTCAATGAGTGGGGCCATGCGTTT
1735|contig:Nitrospira-Wagner|st GTGGTGGGGCCGATGTTCATCTTACCGAACGTGGGGCTCAATGAGTGGGGCCATGCGTTT
******************** ** ************************************
709|contig:Nitrospira-Wagner|sta TGGTTTGTGGACGAGTTGTTTGCGGCGCCGTTGCATTGGGGCTTTGTGACGTTGGGCTGG
1184|contig:Nitrospira-Wagner|st TGGTTTGTGGACGAGTTGTTTGCGGCGCCGTTGCATTGGGGCTTTGTGACGTTGGGCTGG
1735|contig:Nitrospira-Wagner|st TGGTTTGTGGACGAGTTGTTTGCGGCGCCGTTGCATTGGGGCTTTGTGACGTTGGGCTGG
************************************************************
709|contig:Nitrospira-Wagner|sta TGCGGGTTGTTCGGGGCGGCCGGCGGCGTGGCGGCGCAGATTGTGAGCCGCATGTCGAAC
1184|contig:Nitrospira-Wagner|st TGCGGGTTGTTTGGGGCGGCGGGCGGCGTGGCGGCGCAGATTGTGAGCCGCATGTCGAAC
1735|contig:Nitrospira-Wagner|st TGCGGGTTGTTTGGGGCGGCGGGCGGCGTGGCGGCGCAGATTGTGAGCCGCATGTCGAAC
*********** ******** ***************************************
709|contig:Nitrospira-Wagner|sta TTGGCGGATGTGATTTGGAACGGGGCGCCCAAGAGCATCCTGGATCCGTTCCCCAGCCAG
1184|contig:Nitrospira-Wagner|st TTGGCGGATGTGATTTGGAACGGGGCGCCCAAGAGCATCCTGGATCCGTTCCCCAGCCAG
1735|contig:Nitrospira-Wagner|st TTGGCGGATGTGATTTGGAACGGGGCGCCCAAGAGCATCCTGGATCCGTTCCCCAGCCAG
************************************************************
709|contig:Nitrospira-Wagner|sta GTCAACCCCAACGCCAAAGCAGGCTACTAG
1184|contig:Nitrospira-Wagner|st GTCAACCCCAACGCCAAAGCAGGATACTGA
1735|contig:Nitrospira-Wagner|st GTCAACCCCAACGCCAAAGCAGGATACTGA
*********************** ****
So far so good, and this is what I know about all these:
- There are three AmoC, with anvi’o gene caller ids 709, 1184, and 1735, in anvi’o splits number 368, 606, and 895, respectively.
- The alignment shows that AmoC-1184-in-split-606 and AmoC-1735-in-split-895 are identical, and AmoC-709-in-split-368 is slightly different from both.
- The decrease in coverage is common to all AmoC genes, which is extremely interesting, and there are variable positions for all.
An application of oligotyping in the metagenomic context: Oligotyping AmoC
One question worth going after is this: are the low frequency nucleotides at variable positions in AmoC coming from different reads, or is there a family of reads that that differ from the context they are being mapped to at each variable position?
Let’s focus on these three nucleotide positions in AmoC-1735-in-split-895:
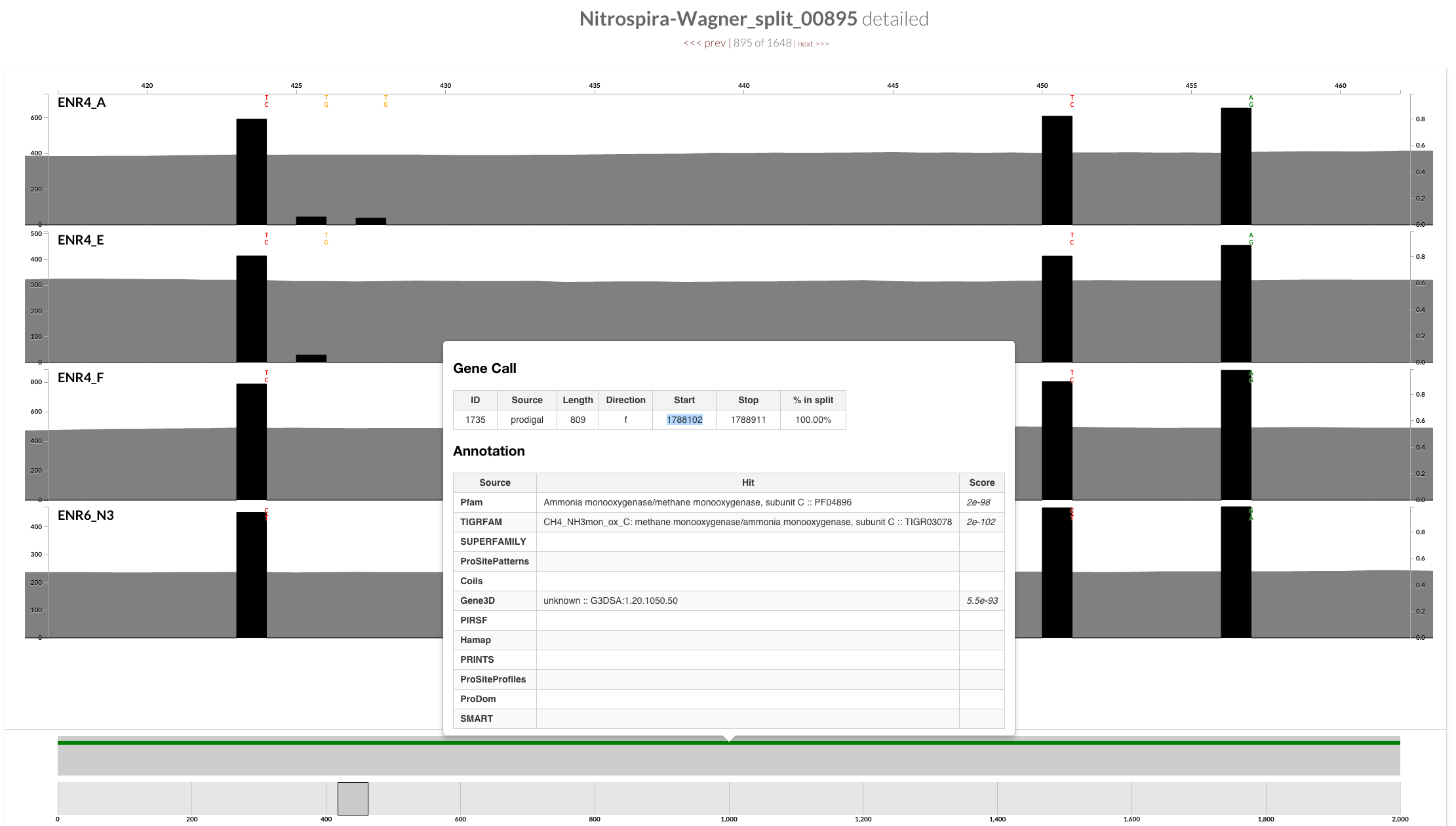
If you look at the alignment of three AmoC genes, you will realize that the variable positions in this figure correspond to the following positions where two unique AmoC differ in this genome:
(...)
709|contig:Nitrospira-Wagner|sta TGGATGGGGTGGTTGGCCTGCTACGTGTGGGGGGTCTATTATGCGGGCAGCTACACGTTG
1184|contig:Nitrospira-Wagner|st TGGATGGGGTGGTTGGCCTGCTATGTGTGGGGGGTCTATTATGCGGGCAGTTACACATTG
1735|contig:Nitrospira-Wagner|st TGGATGGGGTGGTTGGCCTGCTATGTGTGGGGGGTCTATTATGCGGGCAGTTACACATTG
*********************** ************************** ***** ***
^ ^ ^
(...)
It is as if reads that must have been mapped to the context of AmoC-709-in-split-368, ended up being mapped to the context of AmoC-1735-in-split-895. But is it the case? We can easily get our answer by oligotyping this region!
For an oligotyping analysis one can ask anvi’o to report back all short reads in a BAM file that cover each nucleotide position of interest (of course the maximum distance of these nucleotide positions should be smaller than the length of the short reads). For this I created a TAB-delimited file with the contig name I am interested in, and the nucleotide positions I recovered using the gene start position (see the figure above):
$ cat AmoC-1735-variable-pos.txt
Nitrospira-Wagner 1788424,1788451,1788457
Then I called anvi-report-linkmers:
$ anvi-report-linkmers --contigs-and-positions AmoC-1735-variable-pos.txt \
-i BAMs/*.bam \
-o AmoC-1735-linkmers.txt \
--only-complete-links
Working on 'ENR4-A'
=====================================
input_bam_path .....................: /Users/meren/MERGED/BAMs/ENR4-A.bam
sample_id ..........................: ENR4-A
total_reads_mapped .................: 6,634,027
num_contigs_in_bam .................: 1
data ...............................: 1208 entries identified mapping at least one of the nucleotide positions for "Nitrospira-Wagner"
data ...............................: 360 unique reads that covered all positions were kept
Working on 'ENR4-E'
=====================================
input_bam_path .....................: /Users/meren/MERGED/BAMs/ENR4-E.bam
sample_id ..........................: ENR4-E
total_reads_mapped .................: 4,905,974
num_contigs_in_bam .................: 1
data ...............................: 959 entries identified mapping at least one of the nucleotide positions for "Nitrospira-Wagner"
data ...............................: 281 unique reads that covered all positions were kept
Working on 'ENR4-F'
=====================================
input_bam_path .....................: /Users/meren/MERGED/BAMs/ENR4-F.bam
sample_id ..........................: ENR4-F
total_reads_mapped .................: 9,040,212
num_contigs_in_bam .................: 1
data ...............................: 1481 entries identified mapping at least one of the nucleotide positions for "Nitrospira-Wagner"
data ...............................: 432 unique reads that covered all positions were kept
Working on 'ENR6_N3'
=====================================
input_bam_path .....................: /Users/meren/MERGED/BAMs/ENR6_N3.bam
sample_id ..........................: ENR6_N3
total_reads_mapped .................: 4,492,930
num_contigs_in_bam .................: 1
data ...............................: 715 entries identified mapping at least one of the nucleotide positions for "Nitrospira-Wagner"
data ...............................: 214 unique reads that covered all positions were kept
output_file ........................: AmoC-1735-linkmers.txt
This program returns a very elaborate description of each nucleotide for each position coming from reads that are mapping to all positions described in the input file. Here is a small snippet from my result:
| entry_id | sample_id | request_id | contig_name | pos_in_contig | pos_in_read | base | read_unique_id | read_X | reverse | sequence |
|---|---|---|---|---|---|---|---|---|---|---|
| 000000001 | ENR4-A | 001 | Nitrospira-Wagner | 1788424 | 265 | T | 472d77a6b981d45c13e44 | read-1 | False | TTGGGTGGTTTGCGATGTTGGCGATTGGGATTTTTTGGGTATTGTATCAGCGGACGTTTGGGTATTCGCACGGG |
| 000000002 | ENR4-A | 001 | Nitrospira-Wagner | 1788424 | 264 | T | 3f4953d9268636f1ee707 | read-1 | True | TGGGTGGTTTGCGATGTTGGCGATTGGGAGTGTTTGGGTATTGTATCAGCGGACGTTTGGGTATTCGCACGGGT |
| 000000003 | ENR4-A | 001 | Nitrospira-Wagner | 1788424 | 264 | T | c4e7c2726b1b9c2c74ee4 | read-1 | True | GGGGTGGTTTGCGATGTTGGCGATTGGGATTTTTTGGGTATTGTATCAGCGGACGTTTGGGTATTCGCACGGGT |
| 000000004 | ENR4-A | 001 | Nitrospira-Wagner | 1788424 | 260 | C | 3dacf6fae6dc74d2b4a81 | read-1 | False | TGGTTTGCGATGTTGGCGATTGGGATTTTTTGGGTATTGTATCAGCGGACGTTTGGGTATTCGCACGGGTTGGA |
| (…) | (…) | (…) | (…) | (…) | (…) | (…) | (…) | (…) | (…) | (…) |
| 000001505 | ENR4-E | 001 | Nitrospira-Wagner | 1788451 | 146 | C | 01d6264659ea515b5166d | read-2 | False | TTATTTTTTGCGATTGCGGTGGGGTGGATTTGGGTGACGCGGGATCGGAATTTGGCGAATTTGGATCCGAAGAC |
| 000001506 | ENR4-E | 001 | Nitrospira-Wagner | 1788451 | 145 | T | 88840e19bc32b29aeab71 | read-1 | False | TATTTTTTGCGATTGCGGTGGGGTGGATTTGGGTGACGCGGGATCGGAATTTGGCGAATTTGGATCCGAAGACG |
| 000001507 | ENR4-E | 001 | Nitrospira-Wagner | 1788451 | 145 | C | d204858e286a2d076e9a1 | read-1 | True | TATGTTTTGCGATTGCGGTGGGGTGGATTTGGGTGACGCGGGATCGGAATTTGGCGAATTTGGATCCGAAGACG |
| 000001508 | ENR4-E | 001 | Nitrospira-Wagner | 1788451 | 144 | T | e8484f97a7d1052c7c7b1 | read-1 | True | TTTGTTTGCGAGTGCGGTGGGGTGGGTGTGGGTGACGCGGGATCGGAATTTGGCGAATTTGGATCCGAAGACGG |
| 000001509 | ENR4-E | 001 | Nitrospira-Wagner | 1788451 | 143 | C | 361b0d83279e4ddb02553 | read-2 | True | TTTGTGGGGGTTGGGGTGGGGTGGATGTGGGTGAGGGGGGGTCGGAATTTGGCGAATTTGGATCCGAAGGCGGA |
| 000001510 | ENR4-E | 001 | Nitrospira-Wagner | 1788451 | 144 | T | 438c570946adff5ffa778 | read-2 | True | CACGACGCTCTGCCGATTTGGGGTGAGTTGGGTGACGCGGGGTCGGAATTTGGCGGATTTGGATCCGAAGACGG |
| 000001511 | ENR4-E | 001 | Nitrospira-Wagner | 1788451 | 142 | C | 895a66a3b93e7c264e637 | read-1 | True | TTTTTGCGATGTGTGGGGGGTGAGTTTGGGTGACTCGGGATGGGAATTTGGCGAATGTGGATCCGAAGACGGAG |
| (…) | (…) | (…) | (…) | (…) | (…) | (…) | (…) | (…) | (…) | (…) |
| 000001512 | ENR4-E | 001 | Nitrospira-Wagner | 1788451 | 138 | C | d3febfdfe4cee6b5ea17e | read-1 | False | TGCGATTGCGGTGGGGTGGATTTGGGTGACGCGGGATCGGAATTTGGCGAATTTGGATCCGAAGACGGAGTTGA |
| 000001513 | ENR4-E | 001 | Nitrospira-Wagner | 1788451 | 138 | T | 635cb64e61ee84a7ffa5e | read-2 | False | TGCGATTGCGGTGGGGTGGATTTGGGTGACGCGGGATCGGAATTTGGCGAATTTGGATCCGAAGACGGAGTTGA |
| 000001514 | ENR4-E | 001 | Nitrospira-Wagner | 1788451 | 137 | T | 9168e814e801a665b4e99 | read-2 | True | GTGTTGTGGGGGGGGGTGATTTTGGTGACTGGGGTGTGGAATTTGGCGAAGTTTGGTCCGAAGACGGAGTGGAA |
| 000002715 | ENR4-F | 001 | Nitrospira-Wagner | 1788451 | 61 | C | 0ba23966e31f39cda8a3f | read-2 | True | GGGATTTTTGCTTGATGGGGTGGTTGGCCTGCTACGTGTGGGGGGTCTATTATGCGGGCAGCTACACGTTGGAG |
| 000002716 | ENR4-F | 001 | Nitrospira-Wagner | 1788451 | 60 | C | 1f661e7c6bf7260eb50e2 | read-1 | True | GTATTGTTACTGGATGGGGTGGTTGGCCTGCTACGTGTGGGGGGTCTATTATGCGGGCAGCTACACGTTGGAGC |
| 000002717 | ENR4-F | 001 | Nitrospira-Wagner | 1788451 | 60 | T | 67c872c6a20b4f5cb973f | read-1 | True | GTATTTTGACTGGATGGGGTGGTTGGCCTGCTATGTGTGGGTGGTCTATTATGCGGGCAGTTACACATTGGGGC |
| (…) | (…) | (…) | (…) | (…) | (…) | (…) | (…) | (…) | (…) | (…) |
| 000003318 | ENR6_N3 | 001 | Nitrospira-Wagner | 1788424 | 136 | T | b25a4190bebab8f825dcb | read-2 | False | ACATTGTGGCCAATGCGTTATTTTTTGCGATTGCGGTGGGGTGGATTTGGGTGACGCGGGATCGGAATTTGGCG |
| 000003319 | ENR6_N3 | 001 | Nitrospira-Wagner | 1788424 | 136 | T | b26b8a59a5300aee793cf | read-2 | False | ACATTGTGGCCAATGCGTTATTTTTTGCGATTGCGGTGGGGTGGATTTGGGTGACGCGGGATCGGAATTTGGCG |
| 000003320 | ENR6_N3 | 001 | Nitrospira-Wagner | 1788424 | 136 | T | b7e559b05af95387c20ef | read-2 | True | ACATTGTGGCCTATGCGTTATTGTTTGCGATTGCGGTGGGGTGGATTTGGGTGACGCGGGATCGGAATTTGGCG |
| 000003321 | ENR6_N3 | 001 | Nitrospira-Wagner | 1788424 | 151 | T | d5056d25b5a2e365e1fb8 | read-1 | True | AGATTGTTGACGGTGACTGGAGTTCAGACGTGGGCGTTTCCGATCTTGCGGTGGGGTGGATTTGGGTGACGCGG |
| 000003322 | ENR6_N3 | 001 | Nitrospira-Wagner | 1788424 | 135 | C | faa1842bf722a6675e461 | read-2 | True | CCTTGTGGGCAATGCGTTATTTTTGTCGATTGCGGTGGGGTGGAGTTGGGTGACGCGGGATCGGAATTTGGCGA |
Although it is not so easy to make sense of this rich output, luckily there is another program to process this information:
$ anvi-oligotype-linkmers -i AmoC-1735-linkmers.txt
Oligotyping outputs per request
===============================================
Output .......................................: oligotype-counts-001.txt
Here is our answer:
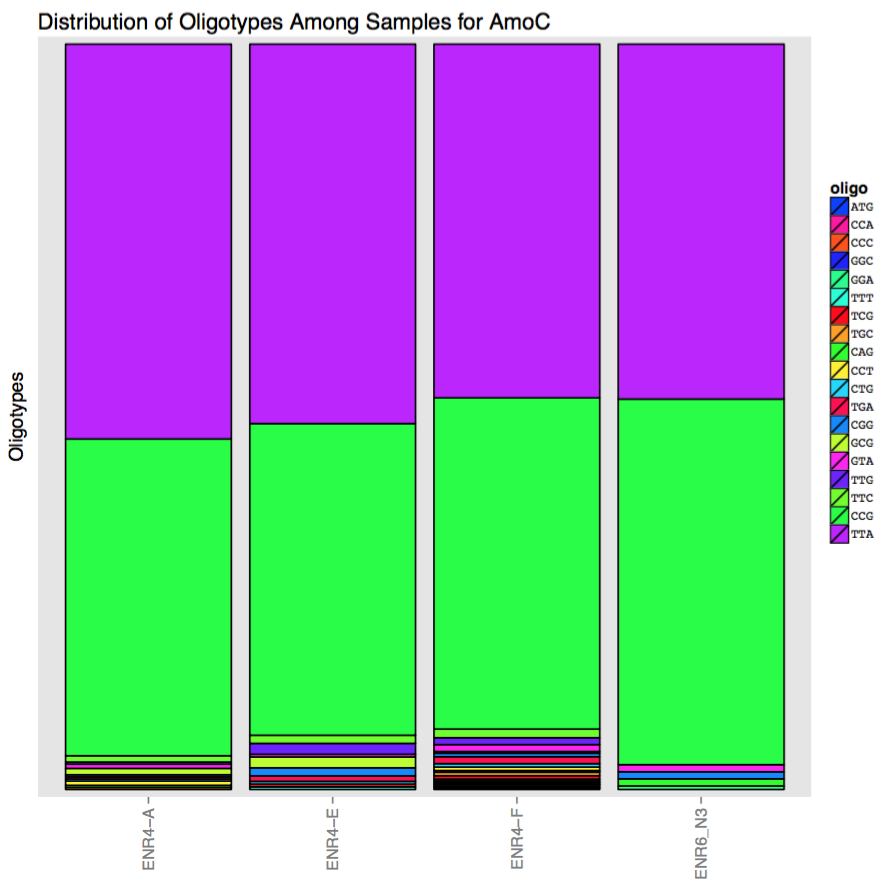
| key | ATG | CAG | CCA | CCC | CCG | CCT | CGG | CTG | GCG | GGA | GGC | GTA | TCG | TGA | TGC | TTA | TTC | TTG | TTT |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ENR4-A | 0 | 3 | 0 | 0 | 450 | 6 | 3 | 3 | 9 | 0 | 0 | 6 | 0 | 3 | 3 | 561 | 9 | 3 | 0 |
| ENR4-E | 0 | 0 | 0 | 0 | 345 | 0 | 9 | 3 | 12 | 0 | 0 | 3 | 3 | 6 | 0 | 420 | 9 | 12 | 3 |
| ENR4-F | 3 | 3 | 3 | 3 | 576 | 6 | 6 | 6 | 3 | 3 | 3 | 12 | 6 | 12 | 6 | 615 | 15 | 12 | 3 |
| ENR6_N3 | 0 | 6 | 0 | 0 | 309 | 0 | 6 | 0 | 0 | 3 | 0 | 6 | 0 | 0 | 0 | 300 | 0 | 0 | 0 |
It seems the variation is not random, and it mostly is created by two read families. Here is a simple visualization of this matrix to make it even more obvious:
And by the way, yes, ENR3 samples and ENR6 do group separately based on the oligotypes (this is an MDS ordination generated by metaMDS in vegan):

But this is where it gets very interesting:
It is clear that reads identified by oligotype CCG seem to be more fitting to AmoC-709-in-split-368. So why did they get mapped to AmoC-1735-in-split-895? I already showed that both BWA and Bowtie2 agrees with the decrease in coverage, and where the variable positions are. But nevertheless I will agree with you if you insist that the simplest explanation is still the mapping step that went wrong, and reads that should have been mapped to the context of AmoC-709-in-split-368 ended up getting mapped to the context of AmoC-1735-in-split-895.
To test this, I asked anvi’o to give me all the short reads from ENR4-A.bam that are mapped to AmoC-1735-in-split-895:
$ anvi-get-short-reads-mapping-to-a-gene --gene-caller-id 1735 \
-c CONTIGS.db \
-i BAMs/ENR4-A.bam \
-o ENR4-A-reads-mapping-to-1735.fa
Contigs DB ...................................: Initialized: CONTIGS.db (v. 4)
Contig .......................................: Nitrospira-Wagner
Gene id ......................................: 1,735
Gene length ..................................: 809
Leeway .......................................: 100
Mapping range start in contig ................: 1,788,202
Mapping range end in contig ..................: 1,788,811
Actual length of mapping window ..............: 609
Working on 'ENR4-A'
===============================================
input_bam_path ...............................: BAMs/ENR4-A.bam
sample_id ....................................: ENR4-A
total_reads_mapped ...........................: 6,634,027
num_contigs_in_bam ...........................: 1
data .........................................: 1384 reads identified mapping between positions 1788202 and 1788811 in "Nitrospira-Wagner"
output_file ..................................: ENR4-A-reads-mapping-to-1735.fa
There I have the 1,384 reads that maps to this gene. Next, I created a FASTA file with only the two unique sequences of three AmoC:
$ anvi-get-dna-sequences-for-gene-calls -c CONTIGS.db \
-o AmoC-unique-sequences.fa \
--gene-caller-ids 709,1735
Then used blastn to BLAST all 1,384 reads Bowtie2 aligned to the context of AmoC-1735-in-split-895 against the two competing AmoC sequences by asking a minimum of 99.25% sequence identity. I hope it is clear that if Bowtie2 made a mistake, almost half of these reads should best match to AmoC-709-in-split-368.
$ makeblastdb -in AmoC-unique-sequences.fa -dbtype nucl
$ blastn -query ENR4-A-reads-mapping-to-1735.fa \
-db AmoC-unique-sequences.fa \
-out output.b6 \
-outfmt '6' \
-perc_identity 99.25
$ wc -l output.b6
378 output.b6
BLASTing gave back 378 unique hits (I made sure manually that they’re all unique). The rest of the reads hit below 99.25% most probably due to sequencing errors, which is not surprising given the 300 nts length of these reads I used for this step.
When I took a look at the distribution of best hits, it was clear that Bowtie2 did a good job at finding the best position for almost all of them, as blastn agreed that the vast majority of reads ended up in the context of AmoC-1735-in-split-895 because there really was no other place for them to go:
$ awk '{print $2}' output.b6 | awk 'BEGIN{FS="|"}{print $1}' | sort | uniq -c
373 1735
5 709
So it goes.
Final words
Here where I keep my promise I made at the very beginning: There are no final words.
I am learning to accept to fact that we are going to be missing a great deal of things, and left great deal of questions unanswered even when we do our best with our data, and that’s OK. Because at some point one has to stop analyzing, and write the study. But making sure the raw data is available is critical. Even the simplest metagenomes are too complex to fully describe, and I have so much respect for people who got us all this far.
I also thank Michael Wagner and his colleagues for their contribution.